I think I'm basically done with my photos, but I still have one where I'm not sure about the subjects. This photo shows the quarterback (Todd, 14) passing the ball, but I am unable to tell whether it's a forward pass or a lateral. There just isn't enough information in the picture--mainly because it doesn't show who is receiving the pass.
All I've got is the QB passing to somebody while offensive players run toward him and another player defends him. Another Alabama player is on the ground off to the left. The news story says that Todd had the ball more than once in some of the scoring drives, so I can't assume this is the first pass of the play. It's not part of a sequence, so I can't get context there, either, though based on the numbering sequence, it's probably this play in the 3rd quarter where Todd passes twice:
"Todd passed for 10 yards to Brown to the Tennessee 28, Calvin Culliver ran five yards, Todd ran nine to the 12, Taylor ran six to the four. Alabama was penalized five yards, and Todd scored from the nine." (Tuscaloosa News, Oct. 19, 1975)
Generic "passing" isn't one of the subject choices, so I have to either choose "lateral" or "forward pass" or leave it out entirely. Leaving it out doesn't seem right since the subject of the picture is obviously some kind of passing, so I've chosen "lateral" basically because the players are kind of spread out, so I think it's not a "line of scrimmage" situation. I'm not totally comfortable with my choice, though.
Christy's subject descriptions are awesome (thank you for providing those, Christy!), but they aren't enough to help me sort out this photo. Could someone look at it and tell me what you think on the lateral vs. forward situation?
http://omeka.slis.ua.edu/ls566-spring2015/alabama-football-images/admin/items/show/id/26
Sunday, April 26, 2015
Figuring out what's going on in those photos
So, I think I have all my images pretty much figured out and described. (Anyone who actually knows anything about football is totally welcome to check out my descriptions and send me feedback if I misidentified anything. I know everyone's busy finishing up, so big thanks in advance if anyone does this.)
The biggest help by far for me was reading the newspaper articles. People with actual knowledge of the game describe the major plays in a way that makes it possible not only to understand what went on in the game, but also to actually match the photos to specific plays. It's super helpful to learn, for example, that a certain player was only on the field in the second half of the game, that a specific scoring drive was dominated by certain players, or the yard line where a play ended.
One Tuscaloosa News article described a play like this: "Davis had the big play in the drive, running 31 yards to the Tennessee nine. Davis broke over guard, raced to the left sideline, and dragged Tennessee players along the way." Lo and behold, one of my photo sequences shows Davis racing along the very edge of the field, pursued by Tennessee players in what is obviously a huge run; the background shows that it was significant yardage and the entry tunnel in the background of the first photo places it at either the Tennessee 40 or the Alabama 35, based on photos of Legion Field. I'm fairly confident from this that I've identified the exact play shown in this photo.
One more hint for the old newspapers: they're scanned from microfilm, so sometimes the pages are sideways. I zoomed in as far as I could, then used the Windows snipping tool (though any screenshot tool will work) to grab images of the articles, pasted them into Word and then rotated them 90 degrees. End result: readable articles.
Here's a list of useful links for anyone still trying to identify plays:
The biggest help by far for me was reading the newspaper articles. People with actual knowledge of the game describe the major plays in a way that makes it possible not only to understand what went on in the game, but also to actually match the photos to specific plays. It's super helpful to learn, for example, that a certain player was only on the field in the second half of the game, that a specific scoring drive was dominated by certain players, or the yard line where a play ended.
One Tuscaloosa News article described a play like this: "Davis had the big play in the drive, running 31 yards to the Tennessee nine. Davis broke over guard, raced to the left sideline, and dragged Tennessee players along the way." Lo and behold, one of my photo sequences shows Davis racing along the very edge of the field, pursued by Tennessee players in what is obviously a huge run; the background shows that it was significant yardage and the entry tunnel in the background of the first photo places it at either the Tennessee 40 or the Alabama 35, based on photos of Legion Field. I'm fairly confident from this that I've identified the exact play shown in this photo.
One more hint for the old newspapers: they're scanned from microfilm, so sometimes the pages are sideways. I zoomed in as far as I could, then used the Windows snipping tool (though any screenshot tool will work) to grab images of the articles, pasted them into Word and then rotated them 90 degrees. End result: readable articles.
Here's a list of useful links for anyone still trying to identify plays:
- Good, clear photo of Legion Field
- Tuscaloosa News (free at Google News Archive) (hint: game coverage on Sundays)
- List of Alabama Online Historical Newspapers
- List of United States Online Historical Newspapers
- The Final Book for the January 2010 game against Texas.
{kind=link}
Sunday, April 19, 2015
Metadata, Achievements, and the Rat-Free Mine
[I wrote this post near the beginning of the semester, when I knew I would be travelling extensively for work over a period of four weeks. I wanted to have some filler posts in reserve in case I got behind. This is the last of those fillers, as it's the most tenuously-related to class content. However, it's a fun topic, and we're nearly done with the course, so why waste it? Happy end of the semester, everyone!]
Sooner or later, people who get to know me find out that I've been playing World of Warcraft (WoW) for the last decade, though graduate school has definitely curtailed my hours in Azeroth. What they may not know is that online games like WoW are a treasure trove of metadata, which is used by both the game companies and the players to a fascinating extent.
From the moment a player creates a character and logs into World of Warcraft for the first, every event that happens to that character is logged, and every option the player chooses to exercise for that character is not only recorded, but factored into the character's performance in the game world. Anyone would expect obvious things to be tracked and factored in, like whether a character has added a better piece of armor or been dealt a damaging blow, has completed the requirements for a specific quest, or accrued enough reputation points with a specific faction to be considered "friendly." But WoW tracks everything, including minutiae like how many fish a character has caught, how many different critters the character has '/love'd, and how many critters the members of a guild have collectively killed.

On the player side, massive websites are dedicated to collecting that stream of metadata and turning it into useful guides that help players with everything from choosing gear to understanding confusing quest instructions to proper etiquette in a raid group. Blizzard, the company that makes WoW, makes an API available so that the player community can design add-ons to the game that leverage this stream of metadata.
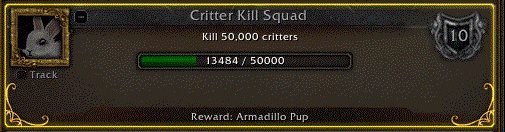
So here's an interesting thing to think about. You might expect that having this metadata available would change player behavior in ways that bring about obvious improvements to the play experience--knowing the best gear for your character class or the best place to find a certain monster are sure winners. However, there's another aspect to this metadata collection, and that is the Achievement System. A very few achievements grant a tangible in-game reward, like a pet, mount, or title. The rest grant nothing more than a filled-in icon in the achievements screen and some "achievement points" that are worth precisely nothing in or out of the game. And yet, despite achievements having ostensibly no value, the mere satisfaction of earning them is enough to drive player behavior. I'm no exception: when I play, I dutifully target every new critter I see in the game world and type "/love" for no other reason than eventually it will earn an achievement. I simply can't help myself, and the comments in WoW player sites tell me I'm not alone. For the same reason, I kill every rat that spawns in the iron mine that's part of my little garrison. I know that if I keep it up, eventually my guild will earn the "Critter Kill Squad" achievement for wiping out 50,000 of the little blighters. I've even incorporated it into my mental roleplaying, "maintaining good hygiene in my mine."
So how on Earth does this apply to libraries and metadata? What if libraries tracked user behavior this carefully? Would it be utterly creepy for libraries to do this even though we are totally OK with online games doing it? What if libraries granted achievements and gave out badges? What would the rewards be? Purely social--perhaps a "leader board" of the most active researchers? A notation on your diploma--"bibliographic searcher extraordinaire"? Extra credit--"added controlled vocabulary metadata tags to 1,000 items in the XX digital library"? How might this fit in with online learning, gamification, and other education trends? Feel free to share your ideas, likes, or dislikes in the comments!
Sooner or later, people who get to know me find out that I've been playing World of Warcraft (WoW) for the last decade, though graduate school has definitely curtailed my hours in Azeroth. What they may not know is that online games like WoW are a treasure trove of metadata, which is used by both the game companies and the players to a fascinating extent.
From the moment a player creates a character and logs into World of Warcraft for the first, every event that happens to that character is logged, and every option the player chooses to exercise for that character is not only recorded, but factored into the character's performance in the game world. Anyone would expect obvious things to be tracked and factored in, like whether a character has added a better piece of armor or been dealt a damaging blow, has completed the requirements for a specific quest, or accrued enough reputation points with a specific faction to be considered "friendly." But WoW tracks everything, including minutiae like how many fish a character has caught, how many different critters the character has '/love'd, and how many critters the members of a guild have collectively killed.
On the player side, massive websites are dedicated to collecting that stream of metadata and turning it into useful guides that help players with everything from choosing gear to understanding confusing quest instructions to proper etiquette in a raid group. Blizzard, the company that makes WoW, makes an API available so that the player community can design add-ons to the game that leverage this stream of metadata.
So here's an interesting thing to think about. You might expect that having this metadata available would change player behavior in ways that bring about obvious improvements to the play experience--knowing the best gear for your character class or the best place to find a certain monster are sure winners. However, there's another aspect to this metadata collection, and that is the Achievement System. A very few achievements grant a tangible in-game reward, like a pet, mount, or title. The rest grant nothing more than a filled-in icon in the achievements screen and some "achievement points" that are worth precisely nothing in or out of the game. And yet, despite achievements having ostensibly no value, the mere satisfaction of earning them is enough to drive player behavior. I'm no exception: when I play, I dutifully target every new critter I see in the game world and type "/love" for no other reason than eventually it will earn an achievement. I simply can't help myself, and the comments in WoW player sites tell me I'm not alone. For the same reason, I kill every rat that spawns in the iron mine that's part of my little garrison. I know that if I keep it up, eventually my guild will earn the "Critter Kill Squad" achievement for wiping out 50,000 of the little blighters. I've even incorporated it into my mental roleplaying, "maintaining good hygiene in my mine."
So how on Earth does this apply to libraries and metadata? What if libraries tracked user behavior this carefully? Would it be utterly creepy for libraries to do this even though we are totally OK with online games doing it? What if libraries granted achievements and gave out badges? What would the rewards be? Purely social--perhaps a "leader board" of the most active researchers? A notation on your diploma--"bibliographic searcher extraordinaire"? Extra credit--"added controlled vocabulary metadata tags to 1,000 items in the XX digital library"? How might this fit in with online learning, gamification, and other education trends? Feel free to share your ideas, likes, or dislikes in the comments!
Saturday, April 18, 2015
Omeka delete worries: how to make a quick backup
This is in response to Becca's post about Omeka's incredibly user-unfriendly delete button. First, ouch, Becca, I'm sorry you had to re-do your work. I've been afraid of accidentally clicking that delete button from the start, but I had no idea it wouldn't even offer a "cancel" or "are you sure" choice. However, Becca's experience has prompted me to look for a back-up plan so I don't have to re-do all my work if I accidentally hit delete. And it turns out there IS a way! So I'm sharing it with everyone so we can give ourselves a fighting chance against Omeka.
Directions for backing up your work:
Directions for backing up your work:
- Log in to Omeka.
- Click on Collections in the left-hand sidebar.
- Locate your collection and click on the number to the far right (Total number of items).
- At the bottom of the page, click dcmes-xml.
- It will download a file.
- Open this file in Notepad and save as text. It's messy but all the information is there and it will give you something to copy and paste from.
- Alternative: If you have Notepad++ installed, you can right click on the file and "Edit in Notepad++" which is a little bit easier to read.
I don't see a way to load this back into Omeka, but at least you can copy/paste all your data.
Is it perfect? No. Is it better than starting from scratch? Yes!
 |
| Click here to download your file. |
 |
| View the XML using Notepad++ |
 |
| Here's what it looks like in plain Notepad. Messy but serviceable! |
Sunday, April 12, 2015
The real McCoy?
So I'm working my way through indexing my 2009 images and find I have some that include Texas player number 12. The roster at http://www.cfbstats.com/2009/team/703/roster.html for Texas for the whole 2009 season shows two players with number 12, Colt McCoy (QB) and Earl Thomas (Safety). The roster at Rolltide.com lists number 12 as the QB, Colt McCoy, and Earl Thomas as 1D. My extremely shaky understanding of the rules suggests to me that if I see number 12 in a photo, it will be McCoy, and Thomas would be assigned a different number for the game ("1D" is a just a mystery).
However, in my photo series MFB_Texas09_KG01640 through ...1643, number 12 is engaged in tackling-type play, uncharacteristic of a QB. The jersey name is completely obscured. I checked some of the other photos from this game that are in classmates' collections, and there is at least one shot displaying number 12 with the name showing very clearly: Thomas. Therefore, I'm going with Thomas, Earl (Texas) for my player name for number 12.
I'm satisfied with my identification here, especially now that I've looked up actual photos of the two players, but totally confused now on the player number and name thing. Can anyone give me some good hints on how I'm supposed to know which player I'm looking at if I have only a jersey number and I can't trust the roster? Also, does anyone have a picture of Colt McCoy in your photo group? If so, what's his jersey number?
However, in my photo series MFB_Texas09_KG01640 through ...1643, number 12 is engaged in tackling-type play, uncharacteristic of a QB. The jersey name is completely obscured. I checked some of the other photos from this game that are in classmates' collections, and there is at least one shot displaying number 12 with the name showing very clearly: Thomas. Therefore, I'm going with Thomas, Earl (Texas) for my player name for number 12.
I'm satisfied with my identification here, especially now that I've looked up actual photos of the two players, but totally confused now on the player number and name thing. Can anyone give me some good hints on how I'm supposed to know which player I'm looking at if I have only a jersey number and I can't trust the roster? Also, does anyone have a picture of Colt McCoy in your photo group? If so, what's his jersey number?
Saturday, April 11, 2015
Thoughts on the final version of the Rights element
I originally viewed the Rights element purely in the context of basic Dublin Core. However, it turned out that Omeka could handle extended versions of the element. This meant that the project could make use of the following choices:
This is what I proposed for the Rights element (just approved by Dr. MacCall, hooray!):
1. Use the basic Rights element.
2. Simple vocab: All rights reserved by the University of Alabama. Permission to reproduce in any format must be requested in writing by contacting the Paul W. Bryant Museum (http://bryantmuseum.com/).
Even though the link doesn't actually link, I thought it would be good to have it in there so users could just copy and paste it (or highlight and click "go to ..."). I chose the base URL rather than the contact page, as that is probably the least likely to change.
- Rights: Simple Dublin Core
- Rights Holder: "A person or organization owning or managing rights over the resource.
- Access Rights: "Information about who can access the resource or an indication of its security status. Access Rights may include information regarding access or restrictions based on privacy, security, or other policies."
This is what I proposed for the Rights element (just approved by Dr. MacCall, hooray!):
1. Use the basic Rights element.
2. Simple vocab: All rights reserved by the University of Alabama. Permission to reproduce in any format must be requested in writing by contacting the Paul W. Bryant Museum (http://bryantmuseum.com/).
Even though the link doesn't actually link, I thought it would be good to have it in there so users could just copy and paste it (or highlight and click "go to ..."). I chose the base URL rather than the contact page, as that is probably the least likely to change.
Wednesday, April 8, 2015
Can the Rights element be optional?
Dr. MacCall posed the following question in a comment on my previous post about the Rights element: "One last question? In what circumstances would this element be optional?"
Obviously, in one sense the answer is "anytime someone wants it to be--this is Dublin Core, so naturally it's optional," but that doesn't really get to the heart of the question, which is really "when might it be appropriate or acceptable for this element to be absent?"
The Dublin Core Metadata Initiative has this to say: "If the rights element is absent, no assumptions can be made about the status of these and other rights with respect to the resource." Based on this, I can think of various circumstances where one might leave it out:
Obviously, in one sense the answer is "anytime someone wants it to be--this is Dublin Core, so naturally it's optional," but that doesn't really get to the heart of the question, which is really "when might it be appropriate or acceptable for this element to be absent?"
The Dublin Core Metadata Initiative has this to say: "If the rights element is absent, no assumptions can be made about the status of these and other rights with respect to the resource." Based on this, I can think of various circumstances where one might leave it out:
- Content that will never be made public. However, in this circumstance someone still holds the rights. This element might also be a good place for a statement clarifying why the content must remain private. If the content is merely embargoed, even if it's for a period of decades, that, too, is related to rights management and would be appropriately noted in Rights.
- Content where the rights are in dispute. It is understandable that a library would not want to take sides or state inaccurate information about this content. However, rather than leaving it blank, it might be better to simply state "Rights under review" so that anyone wanting to use the image would not either assume it is freely available or expect to be able to license the rights easily.
- Orphan works. In the case of works where it can be assumed that copyright applies but the rightsholder is impossible to identify or contact, it would seem simplest to just leave off the rights information. However, that does no favors to would-be users. Better to state that the item is an orphan work or use a phrase like "additional research required."
- Content where the rights are unknown. Again there would be the temptation to simply say nothing, but again it would be better to warn users that the rights situation is murky. "Usage rights undetermined; users are advised to conduct further research" might work in this case.
- Open access content. There is a temptation here to think that there are no rights to worry about. However, even open access content frequently comes with restrictions related to attribution or non-commercial use that should be firmly stated.
- Freely available or public domain content. You could probably leave off the rights statement here, but why make your users do the copyright math or guess at the status when you could just tell them?
- A rushed or understaffed project, or cases where content has been migrated from a different system. In this situation, it might be acceptable to not have the Rights information listed immediately. However, it would still be important to make addition of that element part of a planned later phase of the project.
- The exact same rights information applies to everything in the library. In this case, the digital library could probably get away with a blanket rights statement that is prominently displayed. However, the moment the content is harvested into another system, that blanket statement is lost. A further problem could be a blanket statement on the front page that doesn't show on individual pages, so users coming directly to a content page from a search engine wouldn't see it.
To me, the Rights element has two important purposes. One is to help protect the rightsholder from infringing uses of their content. The other is to inform the user of the rights status of the content and, if possible, make it easy for them to request permission to use it. By always clearly explaining the intellectual property rights of items in digital collections, even if that status is unknown, libraries can help make their patrons aware that not all content is freely available to use in any way they like, and guide them toward ethical habits of use. The constant reminder also serves to highlight the issue of copyright extensions and how changes in the law can have a real effect on how everyone is allowed to use and re-use creative content.
In the end, although I can think of lots of situations in which the Rights element could be left out, but none in which it doesn't seem to me that it would be better to have it in there. However, perhaps I am overthinking this and there is an obvious situation I'm overlooking. What does everyone else think? Dr. MacCall, would you care to weigh in?
Subscribe to:
Posts (Atom)