I think I'm basically done with my photos, but I still have one where I'm not sure about the subjects. This photo shows the quarterback (Todd, 14) passing the ball, but I am unable to tell whether it's a forward pass or a lateral. There just isn't enough information in the picture--mainly because it doesn't show who is receiving the pass.
All I've got is the QB passing to somebody while offensive players run toward him and another player defends him. Another Alabama player is on the ground off to the left. The news story says that Todd had the ball more than once in some of the scoring drives, so I can't assume this is the first pass of the play. It's not part of a sequence, so I can't get context there, either, though based on the numbering sequence, it's probably this play in the 3rd quarter where Todd passes twice:
"Todd passed for 10 yards to Brown to the Tennessee 28, Calvin Culliver ran five yards, Todd ran nine to the 12, Taylor ran six to the four. Alabama was penalized five yards, and Todd scored from the nine." (Tuscaloosa News, Oct. 19, 1975)
Generic "passing" isn't one of the subject choices, so I have to either choose "lateral" or "forward pass" or leave it out entirely. Leaving it out doesn't seem right since the subject of the picture is obviously some kind of passing, so I've chosen "lateral" basically because the players are kind of spread out, so I think it's not a "line of scrimmage" situation. I'm not totally comfortable with my choice, though.
Christy's subject descriptions are awesome (thank you for providing those, Christy!), but they aren't enough to help me sort out this photo. Could someone look at it and tell me what you think on the lateral vs. forward situation?
http://omeka.slis.ua.edu/ls566-spring2015/alabama-football-images/admin/items/show/id/26
Sunday, April 26, 2015
Figuring out what's going on in those photos
So, I think I have all my images pretty much figured out and described. (Anyone who actually knows anything about football is totally welcome to check out my descriptions and send me feedback if I misidentified anything. I know everyone's busy finishing up, so big thanks in advance if anyone does this.)
The biggest help by far for me was reading the newspaper articles. People with actual knowledge of the game describe the major plays in a way that makes it possible not only to understand what went on in the game, but also to actually match the photos to specific plays. It's super helpful to learn, for example, that a certain player was only on the field in the second half of the game, that a specific scoring drive was dominated by certain players, or the yard line where a play ended.
One Tuscaloosa News article described a play like this: "Davis had the big play in the drive, running 31 yards to the Tennessee nine. Davis broke over guard, raced to the left sideline, and dragged Tennessee players along the way." Lo and behold, one of my photo sequences shows Davis racing along the very edge of the field, pursued by Tennessee players in what is obviously a huge run; the background shows that it was significant yardage and the entry tunnel in the background of the first photo places it at either the Tennessee 40 or the Alabama 35, based on photos of Legion Field. I'm fairly confident from this that I've identified the exact play shown in this photo.
One more hint for the old newspapers: they're scanned from microfilm, so sometimes the pages are sideways. I zoomed in as far as I could, then used the Windows snipping tool (though any screenshot tool will work) to grab images of the articles, pasted them into Word and then rotated them 90 degrees. End result: readable articles.
Here's a list of useful links for anyone still trying to identify plays:
The biggest help by far for me was reading the newspaper articles. People with actual knowledge of the game describe the major plays in a way that makes it possible not only to understand what went on in the game, but also to actually match the photos to specific plays. It's super helpful to learn, for example, that a certain player was only on the field in the second half of the game, that a specific scoring drive was dominated by certain players, or the yard line where a play ended.
One Tuscaloosa News article described a play like this: "Davis had the big play in the drive, running 31 yards to the Tennessee nine. Davis broke over guard, raced to the left sideline, and dragged Tennessee players along the way." Lo and behold, one of my photo sequences shows Davis racing along the very edge of the field, pursued by Tennessee players in what is obviously a huge run; the background shows that it was significant yardage and the entry tunnel in the background of the first photo places it at either the Tennessee 40 or the Alabama 35, based on photos of Legion Field. I'm fairly confident from this that I've identified the exact play shown in this photo.
One more hint for the old newspapers: they're scanned from microfilm, so sometimes the pages are sideways. I zoomed in as far as I could, then used the Windows snipping tool (though any screenshot tool will work) to grab images of the articles, pasted them into Word and then rotated them 90 degrees. End result: readable articles.
Here's a list of useful links for anyone still trying to identify plays:
- Good, clear photo of Legion Field
- Tuscaloosa News (free at Google News Archive) (hint: game coverage on Sundays)
- List of Alabama Online Historical Newspapers
- List of United States Online Historical Newspapers
- The Final Book for the January 2010 game against Texas.
{kind=link}
Sunday, April 19, 2015
Metadata, Achievements, and the Rat-Free Mine
[I wrote this post near the beginning of the semester, when I knew I would be travelling extensively for work over a period of four weeks. I wanted to have some filler posts in reserve in case I got behind. This is the last of those fillers, as it's the most tenuously-related to class content. However, it's a fun topic, and we're nearly done with the course, so why waste it? Happy end of the semester, everyone!]
Sooner or later, people who get to know me find out that I've been playing World of Warcraft (WoW) for the last decade, though graduate school has definitely curtailed my hours in Azeroth. What they may not know is that online games like WoW are a treasure trove of metadata, which is used by both the game companies and the players to a fascinating extent.
From the moment a player creates a character and logs into World of Warcraft for the first, every event that happens to that character is logged, and every option the player chooses to exercise for that character is not only recorded, but factored into the character's performance in the game world. Anyone would expect obvious things to be tracked and factored in, like whether a character has added a better piece of armor or been dealt a damaging blow, has completed the requirements for a specific quest, or accrued enough reputation points with a specific faction to be considered "friendly." But WoW tracks everything, including minutiae like how many fish a character has caught, how many different critters the character has '/love'd, and how many critters the members of a guild have collectively killed.

On the player side, massive websites are dedicated to collecting that stream of metadata and turning it into useful guides that help players with everything from choosing gear to understanding confusing quest instructions to proper etiquette in a raid group. Blizzard, the company that makes WoW, makes an API available so that the player community can design add-ons to the game that leverage this stream of metadata.
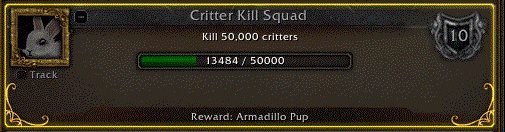
So here's an interesting thing to think about. You might expect that having this metadata available would change player behavior in ways that bring about obvious improvements to the play experience--knowing the best gear for your character class or the best place to find a certain monster are sure winners. However, there's another aspect to this metadata collection, and that is the Achievement System. A very few achievements grant a tangible in-game reward, like a pet, mount, or title. The rest grant nothing more than a filled-in icon in the achievements screen and some "achievement points" that are worth precisely nothing in or out of the game. And yet, despite achievements having ostensibly no value, the mere satisfaction of earning them is enough to drive player behavior. I'm no exception: when I play, I dutifully target every new critter I see in the game world and type "/love" for no other reason than eventually it will earn an achievement. I simply can't help myself, and the comments in WoW player sites tell me I'm not alone. For the same reason, I kill every rat that spawns in the iron mine that's part of my little garrison. I know that if I keep it up, eventually my guild will earn the "Critter Kill Squad" achievement for wiping out 50,000 of the little blighters. I've even incorporated it into my mental roleplaying, "maintaining good hygiene in my mine."
So how on Earth does this apply to libraries and metadata? What if libraries tracked user behavior this carefully? Would it be utterly creepy for libraries to do this even though we are totally OK with online games doing it? What if libraries granted achievements and gave out badges? What would the rewards be? Purely social--perhaps a "leader board" of the most active researchers? A notation on your diploma--"bibliographic searcher extraordinaire"? Extra credit--"added controlled vocabulary metadata tags to 1,000 items in the XX digital library"? How might this fit in with online learning, gamification, and other education trends? Feel free to share your ideas, likes, or dislikes in the comments!
Sooner or later, people who get to know me find out that I've been playing World of Warcraft (WoW) for the last decade, though graduate school has definitely curtailed my hours in Azeroth. What they may not know is that online games like WoW are a treasure trove of metadata, which is used by both the game companies and the players to a fascinating extent.
From the moment a player creates a character and logs into World of Warcraft for the first, every event that happens to that character is logged, and every option the player chooses to exercise for that character is not only recorded, but factored into the character's performance in the game world. Anyone would expect obvious things to be tracked and factored in, like whether a character has added a better piece of armor or been dealt a damaging blow, has completed the requirements for a specific quest, or accrued enough reputation points with a specific faction to be considered "friendly." But WoW tracks everything, including minutiae like how many fish a character has caught, how many different critters the character has '/love'd, and how many critters the members of a guild have collectively killed.
On the player side, massive websites are dedicated to collecting that stream of metadata and turning it into useful guides that help players with everything from choosing gear to understanding confusing quest instructions to proper etiquette in a raid group. Blizzard, the company that makes WoW, makes an API available so that the player community can design add-ons to the game that leverage this stream of metadata.
So here's an interesting thing to think about. You might expect that having this metadata available would change player behavior in ways that bring about obvious improvements to the play experience--knowing the best gear for your character class or the best place to find a certain monster are sure winners. However, there's another aspect to this metadata collection, and that is the Achievement System. A very few achievements grant a tangible in-game reward, like a pet, mount, or title. The rest grant nothing more than a filled-in icon in the achievements screen and some "achievement points" that are worth precisely nothing in or out of the game. And yet, despite achievements having ostensibly no value, the mere satisfaction of earning them is enough to drive player behavior. I'm no exception: when I play, I dutifully target every new critter I see in the game world and type "/love" for no other reason than eventually it will earn an achievement. I simply can't help myself, and the comments in WoW player sites tell me I'm not alone. For the same reason, I kill every rat that spawns in the iron mine that's part of my little garrison. I know that if I keep it up, eventually my guild will earn the "Critter Kill Squad" achievement for wiping out 50,000 of the little blighters. I've even incorporated it into my mental roleplaying, "maintaining good hygiene in my mine."
So how on Earth does this apply to libraries and metadata? What if libraries tracked user behavior this carefully? Would it be utterly creepy for libraries to do this even though we are totally OK with online games doing it? What if libraries granted achievements and gave out badges? What would the rewards be? Purely social--perhaps a "leader board" of the most active researchers? A notation on your diploma--"bibliographic searcher extraordinaire"? Extra credit--"added controlled vocabulary metadata tags to 1,000 items in the XX digital library"? How might this fit in with online learning, gamification, and other education trends? Feel free to share your ideas, likes, or dislikes in the comments!
Saturday, April 18, 2015
Omeka delete worries: how to make a quick backup
This is in response to Becca's post about Omeka's incredibly user-unfriendly delete button. First, ouch, Becca, I'm sorry you had to re-do your work. I've been afraid of accidentally clicking that delete button from the start, but I had no idea it wouldn't even offer a "cancel" or "are you sure" choice. However, Becca's experience has prompted me to look for a back-up plan so I don't have to re-do all my work if I accidentally hit delete. And it turns out there IS a way! So I'm sharing it with everyone so we can give ourselves a fighting chance against Omeka.
Directions for backing up your work:
Directions for backing up your work:
- Log in to Omeka.
- Click on Collections in the left-hand sidebar.
- Locate your collection and click on the number to the far right (Total number of items).
- At the bottom of the page, click dcmes-xml.
- It will download a file.
- Open this file in Notepad and save as text. It's messy but all the information is there and it will give you something to copy and paste from.
- Alternative: If you have Notepad++ installed, you can right click on the file and "Edit in Notepad++" which is a little bit easier to read.
I don't see a way to load this back into Omeka, but at least you can copy/paste all your data.
Is it perfect? No. Is it better than starting from scratch? Yes!
 |
| Click here to download your file. |
 |
| View the XML using Notepad++ |
 |
| Here's what it looks like in plain Notepad. Messy but serviceable! |
Sunday, April 12, 2015
The real McCoy?
So I'm working my way through indexing my 2009 images and find I have some that include Texas player number 12. The roster at http://www.cfbstats.com/2009/team/703/roster.html for Texas for the whole 2009 season shows two players with number 12, Colt McCoy (QB) and Earl Thomas (Safety). The roster at Rolltide.com lists number 12 as the QB, Colt McCoy, and Earl Thomas as 1D. My extremely shaky understanding of the rules suggests to me that if I see number 12 in a photo, it will be McCoy, and Thomas would be assigned a different number for the game ("1D" is a just a mystery).
However, in my photo series MFB_Texas09_KG01640 through ...1643, number 12 is engaged in tackling-type play, uncharacteristic of a QB. The jersey name is completely obscured. I checked some of the other photos from this game that are in classmates' collections, and there is at least one shot displaying number 12 with the name showing very clearly: Thomas. Therefore, I'm going with Thomas, Earl (Texas) for my player name for number 12.
I'm satisfied with my identification here, especially now that I've looked up actual photos of the two players, but totally confused now on the player number and name thing. Can anyone give me some good hints on how I'm supposed to know which player I'm looking at if I have only a jersey number and I can't trust the roster? Also, does anyone have a picture of Colt McCoy in your photo group? If so, what's his jersey number?
However, in my photo series MFB_Texas09_KG01640 through ...1643, number 12 is engaged in tackling-type play, uncharacteristic of a QB. The jersey name is completely obscured. I checked some of the other photos from this game that are in classmates' collections, and there is at least one shot displaying number 12 with the name showing very clearly: Thomas. Therefore, I'm going with Thomas, Earl (Texas) for my player name for number 12.
I'm satisfied with my identification here, especially now that I've looked up actual photos of the two players, but totally confused now on the player number and name thing. Can anyone give me some good hints on how I'm supposed to know which player I'm looking at if I have only a jersey number and I can't trust the roster? Also, does anyone have a picture of Colt McCoy in your photo group? If so, what's his jersey number?
Saturday, April 11, 2015
Thoughts on the final version of the Rights element
I originally viewed the Rights element purely in the context of basic Dublin Core. However, it turned out that Omeka could handle extended versions of the element. This meant that the project could make use of the following choices:
This is what I proposed for the Rights element (just approved by Dr. MacCall, hooray!):
1. Use the basic Rights element.
2. Simple vocab: All rights reserved by the University of Alabama. Permission to reproduce in any format must be requested in writing by contacting the Paul W. Bryant Museum (http://bryantmuseum.com/).
Even though the link doesn't actually link, I thought it would be good to have it in there so users could just copy and paste it (or highlight and click "go to ..."). I chose the base URL rather than the contact page, as that is probably the least likely to change.
- Rights: Simple Dublin Core
- Rights Holder: "A person or organization owning or managing rights over the resource.
- Access Rights: "Information about who can access the resource or an indication of its security status. Access Rights may include information regarding access or restrictions based on privacy, security, or other policies."
This is what I proposed for the Rights element (just approved by Dr. MacCall, hooray!):
1. Use the basic Rights element.
2. Simple vocab: All rights reserved by the University of Alabama. Permission to reproduce in any format must be requested in writing by contacting the Paul W. Bryant Museum (http://bryantmuseum.com/).
Even though the link doesn't actually link, I thought it would be good to have it in there so users could just copy and paste it (or highlight and click "go to ..."). I chose the base URL rather than the contact page, as that is probably the least likely to change.
Wednesday, April 8, 2015
Can the Rights element be optional?
Dr. MacCall posed the following question in a comment on my previous post about the Rights element: "One last question? In what circumstances would this element be optional?"
Obviously, in one sense the answer is "anytime someone wants it to be--this is Dublin Core, so naturally it's optional," but that doesn't really get to the heart of the question, which is really "when might it be appropriate or acceptable for this element to be absent?"
The Dublin Core Metadata Initiative has this to say: "If the rights element is absent, no assumptions can be made about the status of these and other rights with respect to the resource." Based on this, I can think of various circumstances where one might leave it out:
Obviously, in one sense the answer is "anytime someone wants it to be--this is Dublin Core, so naturally it's optional," but that doesn't really get to the heart of the question, which is really "when might it be appropriate or acceptable for this element to be absent?"
The Dublin Core Metadata Initiative has this to say: "If the rights element is absent, no assumptions can be made about the status of these and other rights with respect to the resource." Based on this, I can think of various circumstances where one might leave it out:
- Content that will never be made public. However, in this circumstance someone still holds the rights. This element might also be a good place for a statement clarifying why the content must remain private. If the content is merely embargoed, even if it's for a period of decades, that, too, is related to rights management and would be appropriately noted in Rights.
- Content where the rights are in dispute. It is understandable that a library would not want to take sides or state inaccurate information about this content. However, rather than leaving it blank, it might be better to simply state "Rights under review" so that anyone wanting to use the image would not either assume it is freely available or expect to be able to license the rights easily.
- Orphan works. In the case of works where it can be assumed that copyright applies but the rightsholder is impossible to identify or contact, it would seem simplest to just leave off the rights information. However, that does no favors to would-be users. Better to state that the item is an orphan work or use a phrase like "additional research required."
- Content where the rights are unknown. Again there would be the temptation to simply say nothing, but again it would be better to warn users that the rights situation is murky. "Usage rights undetermined; users are advised to conduct further research" might work in this case.
- Open access content. There is a temptation here to think that there are no rights to worry about. However, even open access content frequently comes with restrictions related to attribution or non-commercial use that should be firmly stated.
- Freely available or public domain content. You could probably leave off the rights statement here, but why make your users do the copyright math or guess at the status when you could just tell them?
- A rushed or understaffed project, or cases where content has been migrated from a different system. In this situation, it might be acceptable to not have the Rights information listed immediately. However, it would still be important to make addition of that element part of a planned later phase of the project.
- The exact same rights information applies to everything in the library. In this case, the digital library could probably get away with a blanket rights statement that is prominently displayed. However, the moment the content is harvested into another system, that blanket statement is lost. A further problem could be a blanket statement on the front page that doesn't show on individual pages, so users coming directly to a content page from a search engine wouldn't see it.
To me, the Rights element has two important purposes. One is to help protect the rightsholder from infringing uses of their content. The other is to inform the user of the rights status of the content and, if possible, make it easy for them to request permission to use it. By always clearly explaining the intellectual property rights of items in digital collections, even if that status is unknown, libraries can help make their patrons aware that not all content is freely available to use in any way they like, and guide them toward ethical habits of use. The constant reminder also serves to highlight the issue of copyright extensions and how changes in the law can have a real effect on how everyone is allowed to use and re-use creative content.
In the end, although I can think of lots of situations in which the Rights element could be left out, but none in which it doesn't seem to me that it would be better to have it in there. However, perhaps I am overthinking this and there is an obvious situation I'm overlooking. What does everyone else think? Dr. MacCall, would you care to weigh in?
Thursday, April 2, 2015
On football familiarity, or lack thereof
Several of us have now confessed to being football-challenged and nervous about being able to do a good job of describing images that just look like a jumble of people in brightly-colored uniforms. I'm in awe of people who can look at an image and somehow divine which team is "offensive" and which is "defensive" and know whether the ball is being thrown, received, or otherwise. I very much appreciate the kind efforts of my fellow classmates to help us out with useful links (shout out to Library Corner for posting those tools!), and I agree with Metadata for Breakfast that there is certainly no guarantee that we'll work with familiar subjects out in the real world, so, yes, it's good experience.
However, I couldn't help wondering if there is a class project that would present a more level playing field (ha!). What if the project were something that was likely to be quite difficult to everyone? Would intramural ultimate frisbee images from several years ago be hard enough? What about a jai alai image collection? Or maybe we should go in the other direction and have images everyone can understand: LOLcats. In fact, I hereby suggest that next year's class, and all classes thereafter, get to use funny cat and dog pictures. Problem solved!

However, I couldn't help wondering if there is a class project that would present a more level playing field (ha!). What if the project were something that was likely to be quite difficult to everyone? Would intramural ultimate frisbee images from several years ago be hard enough? What about a jai alai image collection? Or maybe we should go in the other direction and have images everyone can understand: LOLcats. In fact, I hereby suggest that next year's class, and all classes thereafter, get to use funny cat and dog pictures. Problem solved!
Rights: Your new favorite element
Why will this be your new favorite? Because as long as the client approves this language, it will be the easiest required element in this project! I think I've got this down to one statement that you can copy and paste into the "Rights" box for every image. My only question is whether there should be a second (also easy!) Rights entry with a link to the Museum's contact page. Dr. MacCall implied in an email that we could just say "by contacting the Paul W. Bryant Museum," but I'm worried that it's not enough.
What do you all think? Is it enough? Should we also link to the museum? Is there a significant risk that the museum will someday make changes to its site that break that URL? Is it worse to provide less information up front or to risk having potentially outdated information in our records that we'd have to contend with later (if this was a professional project)?
I'll note here that there is a variation where we just embed the link into the Rights statement. However, when I did this I noticed that the linked text was noticeably lighter than the rest of the statement. I'll paste snips of the two variations below so you can all judge the aesthetics.
Label
Rights
Element Description
This element states the various property rights associated with the resource, including intellectual property rights.
Required?
Yes
Repeatable?
Maybe
Guidelines for Creation of Content
Use the following statement:
All rights reserved by the University of Alabama. Permission to reproduce in any format must be requested in writing by contacting the Paul W. Bryant Museum.
This is the HTML that could go in the second Rights field:
<a href="http://bryantmuseum.ua.edu/direction.cfm?dir=contact" target="_blank">Contact the Paul W. Bryant Museum</a>
Examples
All images use the exact wording and HTML code above.
Notes
The Rights statement may be pasted directly into Omeka. To make the second Rights field, you need to paste in the HTML code and check the "Use HTML" box.

What do you all think? Is it enough? Should we also link to the museum? Is there a significant risk that the museum will someday make changes to its site that break that URL? Is it worse to provide less information up front or to risk having potentially outdated information in our records that we'd have to contend with later (if this was a professional project)?
I'll note here that there is a variation where we just embed the link into the Rights statement. However, when I did this I noticed that the linked text was noticeably lighter than the rest of the statement. I'll paste snips of the two variations below so you can all judge the aesthetics.
Label
Rights
Element Description
This element states the various property rights associated with the resource, including intellectual property rights.
Required?
Yes
Repeatable?
Maybe
Guidelines for Creation of Content
Use the following statement:
All rights reserved by the University of Alabama. Permission to reproduce in any format must be requested in writing by contacting the Paul W. Bryant Museum.
This is the HTML that could go in the second Rights field:
<a href="http://bryantmuseum.ua.edu/direction.cfm?dir=contact" target="_blank">Contact the Paul W. Bryant Museum</a>
Examples
All images use the exact wording and HTML code above.
Notes
The Rights statement may be pasted directly into Omeka. To make the second Rights field, you need to paste in the HTML code and check the "Use HTML" box.
More thoughts on linked data and the future of cataloging
I really enjoyed Slistopher's fun post and article link about the venom library. I wondered about the metadata too, and his suggestion that it could be the project for next year's class cracked me up. But on a more serious note, it prompted me to look up metadata schemas for real, organic things, and it turns out there's a ton of them, this list of schemas being, I am sure, just one of many. And that got me to thinking about linked data and cataloging in world of linked data.
Suppose you had this book on lemurs: Behavioral variation : case study of a Malagasy lemur. Current cataloging techniques give it a several LC subject headings (this is from WorldCat; the older record in my library's catalog uses only the first four):
 in the Grand tsingy.")
Verreaux's sifaka -- Behavior.
Social behavior in animals.
Mammals -- Behavior.
Mammals -- Madagascar.
Behavior, Animal.
Lemuridae.
Social Behavior.
Mammals.
Madagascar.
Lemuren.
Verhalten.
Madagaskar.
Lemurs
In a linked data world, we would reasonably expect that the basic descriptive metadata (author, publisher, identifiers such as ISBN, etc.) would use some kind of permanent identifiers that would allow them to be meaningfully linked to related content. But what about those subjects?
In both WorldCat and my library's catalog, the subjects are clickable links, but clicking them results in a search for that subject only within the catalog. In a more linked environment, would siloized search still be appropriate? Maybe the subject links could bring in lots more things that are linked to that heading using LC's linked data service (e.g. Lemuridae). But is that enough? Will other curators of desirable content use LCSH? Maybe instead of, or at least in addition to, expecting outside entities to conform to library-centric aboutness terminology, cataloging records should link to data hubs appropriate to the content. Just one example in this case is the ITIS taxonomy (e.g. Verreaux's sifaka). That would potentially link this book on the social behavior of a specific type of lemur to scientific articles, datasets, images, and perhaps even its genome. It's not hard to imagine other elements that might link in similar ways: Madagascar, for example, or perhaps even primate social behavior.
Do you think this kind of outside vocabulary will eventually replace LCSH or will it still be important for broad, general categories like "Social Behavior"? Will we still need it for faceted, siloized library searches? Will we still even have the silos?
Suppose you had this book on lemurs: Behavioral variation : case study of a Malagasy lemur. Current cataloging techniques give it a several LC subject headings (this is from WorldCat; the older record in my library's catalog uses only the first four):
Verreaux's sifaka -- Behavior.
Social behavior in animals.
Mammals -- Behavior.
Mammals -- Madagascar.
Behavior, Animal.
Lemuridae.
Social Behavior.
Mammals.
Madagascar.
Lemuren.
Verhalten.
Madagaskar.
Lemurs
In a linked data world, we would reasonably expect that the basic descriptive metadata (author, publisher, identifiers such as ISBN, etc.) would use some kind of permanent identifiers that would allow them to be meaningfully linked to related content. But what about those subjects?
In both WorldCat and my library's catalog, the subjects are clickable links, but clicking them results in a search for that subject only within the catalog. In a more linked environment, would siloized search still be appropriate? Maybe the subject links could bring in lots more things that are linked to that heading using LC's linked data service (e.g. Lemuridae). But is that enough? Will other curators of desirable content use LCSH? Maybe instead of, or at least in addition to, expecting outside entities to conform to library-centric aboutness terminology, cataloging records should link to data hubs appropriate to the content. Just one example in this case is the ITIS taxonomy (e.g. Verreaux's sifaka). That would potentially link this book on the social behavior of a specific type of lemur to scientific articles, datasets, images, and perhaps even its genome. It's not hard to imagine other elements that might link in similar ways: Madagascar, for example, or perhaps even primate social behavior.
Do you think this kind of outside vocabulary will eventually replace LCSH or will it still be important for broad, general categories like "Social Behavior"? Will we still need it for faceted, siloized library searches? Will we still even have the silos?
Saturday, March 28, 2015
More Thoughts on the Rights Element
The Rights Element is one of the most straightforward of the elements in terms of what it should contain and why it is there. By definition, it simply "includes a statement about various property rights associated with the resource, including intellectual property rights." Operationally, it establishes who the rightsholder is and frequently offers contact information for prospective users.
I looked over the guidelines linked from our wiki and I think the CARLI version is probably the most straightforward and applicable to our project. The left side is simply labeled "Rights" and the right side is both non-threatening in tone and clear in its intent and directions. I particularly like the second example:
In the meantime, how is this looking to everyone? Feedback welcome!
I looked over the guidelines linked from our wiki and I think the CARLI version is probably the most straightforward and applicable to our project. The left side is simply labeled "Rights" and the right side is both non-threatening in tone and clear in its intent and directions. I particularly like the second example:
Here is an actual example from the Great Lakes Digital Collection (Newberry Library):All rights held by William Rainey Harper College Archives. For permission to reproduce, distribute, or otherwise use this image, please contact Firstname Lastname at xxx@harpercollege.edu.
Rights All rights reserved by the Newberry Library. Permission to reproduce in any format must be requested in writing. Contact Photoduplication Department, Newberry Library, 60 W. Walton St., Chicago, IL 60610. Phone: 312-255-3566. E-mail: photoduplication@newberry.orgI think this would translate into one simple statement that could be used for every image, something like:
Rights All rights reserved by the University of Alabama. Permission to reproduce in any format must be requested in writing. Contact [appropriate department at UA, phone: ____, email:____ ]Right now I'm trying to find out what department that will actually be. Several departments seem to hold licensing rights to images and trademarks: Office of University Advancement, University Athletics, Hoole Library, even the Office of Archaeological Research. I've requested clarification on ownership from the client.
In the meantime, how is this looking to everyone? Feedback welcome!
Thursday, March 26, 2015
A Different Kind of Controlled Vocabulary
I read Adam's post about his difficult element, Relation, and it also made me think about some of the other elements that require descriptions that don't necessarily have a straightforward controlled vocabulary to use. How do you achieve consistency of description while still retaining the freedom that allows those less-controlled elements to serve as a useful complement to the more-controlled elements?
For example, if Subject requires a CV that limits it to specific words and phrases like "Tackling" and "Quarterback sack," description might fill in the gaps with keyword-heavy phrases describing the play in more detail. The job of the Relation element would be to link the images of this play, perhaps from the beginning of an attempted tackle through another player's attempt to block and ending with a successful sack.
As long as all the image catalogers are using basically the same style for these elements, all will be well. However, if one describer says "Auburn Right Tackle Smith launches himself" and another says "Tiger offensive lineman number 89 attempts sack" while a third says "Auburn player tries to stop Alabama players by using interpretive dance," then it's not as useful. And I'm going to admit right up front that that third describer is probably me, so I'm concerned about holding up my part of the job when it comes to actually describing these images according to the rules!
That got me to thinking about newspaper and magazine writing, and it occurred to me that they use style guides. So maybe there's a football writing style guide out there that could help all of us to be consistent yet creative and thorough in our descriptions? I looked around and there are some possible choices. Maybe the owners of the more descriptive elements would be kind to the football-challenged among us and consider making a style guide recommended practice for our digital library. Here are a few examples, but there are probably more out there, or the owners of the appropriate elements might just list some suggested terminology and style:
For example, if Subject requires a CV that limits it to specific words and phrases like "Tackling" and "Quarterback sack," description might fill in the gaps with keyword-heavy phrases describing the play in more detail. The job of the Relation element would be to link the images of this play, perhaps from the beginning of an attempted tackle through another player's attempt to block and ending with a successful sack.
As long as all the image catalogers are using basically the same style for these elements, all will be well. However, if one describer says "Auburn Right Tackle Smith launches himself" and another says "Tiger offensive lineman number 89 attempts sack" while a third says "Auburn player tries to stop Alabama players by using interpretive dance," then it's not as useful. And I'm going to admit right up front that that third describer is probably me, so I'm concerned about holding up my part of the job when it comes to actually describing these images according to the rules!
That got me to thinking about newspaper and magazine writing, and it occurred to me that they use style guides. So maybe there's a football writing style guide out there that could help all of us to be consistent yet creative and thorough in our descriptions? I looked around and there are some possible choices. Maybe the owners of the more descriptive elements would be kind to the football-challenged among us and consider making a style guide recommended practice for our digital library. Here are a few examples, but there are probably more out there, or the owners of the appropriate elements might just list some suggested terminology and style:
Wednesday, March 25, 2015
A Different Kind of Schema
Tonight in class, Dr. MacCall talked about ways to automate, or partially automate, metadata entry in digital libraries. While highly sophisticated automation is beyond the scope of our class project, it's useful to be aware of the possibilities in case we need them later in our careers. Using our football image library, Dr. MacCall suggested as an example that perhaps instead of manually typing in a whole, possibly difficult-to-spell name (e.g "Baumhower") every time, the image cataloger could instead type in the player number (in this case, 73) and lookup software would provide the correct name.
Of course, it couldn't really be that simple, and the discussion quickly turned to all the ways it could go wrong (reassigned numbers, duplicate numbers, partial numbers, and so on), as well as the myriad rules for uniform numbers allowed on the field every game. I never realized that football uniform numbers were so complicated! Furthermore, that complicated uniform number system would have to be written into the rules of the number-to-name matching software. Thus numbering rules intended to reduce confusion on the actual football field would be re-purposed as a schema intended to reduce errors in a virtual library of football images. How wonderfully poetic to think that the rules and structure of the game itself could become an integral part of creating a football image library!
Of course, it couldn't really be that simple, and the discussion quickly turned to all the ways it could go wrong (reassigned numbers, duplicate numbers, partial numbers, and so on), as well as the myriad rules for uniform numbers allowed on the field every game. I never realized that football uniform numbers were so complicated! Furthermore, that complicated uniform number system would have to be written into the rules of the number-to-name matching software. Thus numbering rules intended to reduce confusion on the actual football field would be re-purposed as a schema intended to reduce errors in a virtual library of football images. How wonderfully poetic to think that the rules and structure of the game itself could become an integral part of creating a football image library!
Tuesday, March 24, 2015
ER&L 2015
I really enjoyed Adam's post on ARLIS 2015. It sounds like he had a great time and got a lot out of his conference experience. I recommend to everyone to try to get to a library conference if you can, and I also totally recommend the smaller, more narrowly focused conferences. If you're a first-timer, the smaller events are much less overwhelming, you'll have a better chance to meet people in your chosen field, and like Adam, you'll probably find that a majority of the presentations are directly relevant to your interests.
I also thank Adam for reminding me that I could blog about my experience at ER&L 2015. I won a travel grant from Taylor & Francis that paid my way to Austin for this great conference on Electronic Resources and Libraries. The conference had a nice mix of programming, with a lot aimed at new electronic resources managers, as well as a healthy number of presentations on more advanced topics. Discovery was a hot topic, with several presentations and two different panels, one comparing experiences with different systems, and another analyzing products to see if they favored one publisher's or platform's content over another's (happily, they didn't find evidence of favoritism). Lots of presenters mentioned metadata in a variety of contexts--usage data (improving standards, collection assessment), journal metadata (TRANSFER and PIE-J and "publishers, whatever you do, please stop with the retroactive title changes"), user data and privacy (analyzing data, new NISO initiative), discovery (which system delivers the best relevancy ranking for results?), altmetrics (measuring the impact of scholarship), and interoperability (what were the challenges of migration to this next generation system?). Of course I couldn't get to everything I wanted to hear, but I had a blast trying and would recommend ER&L to anyone starting or considering a career in electronic resources management, collection assessment, or a related job.
I also thank Adam for reminding me that I could blog about my experience at ER&L 2015. I won a travel grant from Taylor & Francis that paid my way to Austin for this great conference on Electronic Resources and Libraries. The conference had a nice mix of programming, with a lot aimed at new electronic resources managers, as well as a healthy number of presentations on more advanced topics. Discovery was a hot topic, with several presentations and two different panels, one comparing experiences with different systems, and another analyzing products to see if they favored one publisher's or platform's content over another's (happily, they didn't find evidence of favoritism). Lots of presenters mentioned metadata in a variety of contexts--usage data (improving standards, collection assessment), journal metadata (TRANSFER and PIE-J and "publishers, whatever you do, please stop with the retroactive title changes"), user data and privacy (analyzing data, new NISO initiative), discovery (which system delivers the best relevancy ranking for results?), altmetrics (measuring the impact of scholarship), and interoperability (what were the challenges of migration to this next generation system?). Of course I couldn't get to everything I wanted to hear, but I had a blast trying and would recommend ER&L to anyone starting or considering a career in electronic resources management, collection assessment, or a related job.
Monday, March 23, 2015
Rights Vocabulary: the publisher situation
While I was already thinking about Rights vocabulary, the Copyright Clearance Center conveniently tweeted a link to this post about the massive scale of rights and royalties that publishers must deal with, and ways they are considering to automate or at least improve the process. Rights and royalty data, it turns out, are a bit of a Wild West situation, with practically no standardization, and publishers "still receiving royalty statements from their licensees in all imaginable formats — PDFs, Excel documents, and even paper printouts."
Although the issue of ultimately funding the initiative is still up in the air, the Book Industry Study Group's (BISG) Rights Committee has begun work associated with three major themes: the value of standardization and how it will provide return on investment, development of a standard vocabulary of rights terminology, and ways to improve the visibility and discoverability of rights.
As the publishing industry continues to consolidate, with the resulting need to combine massively varied licensing data and control ever larger numbers of assets, the need to automate this process and create interoperability will become increasingly pressing. While publishers have been getting along without standardization and automation thus far, it seems likely that the industry as a whole will become convinced that enough return can be made on the investment, and will move forward on this issue.
Rights Vocabulary for Digital Libraries
Since the Rights Element is my responsibility for our class project, I have been thinking about the appropriate language to use to make sure the information is both understandable and reasonably aligned with rights language in other digital libraries. I checked to see if there is a controlled vocabulary that we might use, but found that while much attention has been paid to structure and rules, actual right-hand-side standard terms don't seem to have one standard list. This list of licensing vocabulary from Center for Research Libraries has some useful terms, but it is mostly intended for licensing electronic resources such as databases, journals, and books. PRISM offers a very minimal list of right terms. Creative Commons provides a clearer set of terminology, adapted for RDF, and several linked data licensing vocabularies are rounded up on this handy site.
For our project, keeping it simple will probably be the best course of action, but it is interesting to see how this might be handled in a linked data environment--and to realize how important proper encoding of rights data could be in an environment where the images in your digital library could be linked to outside resources in unexpected or imagined ways.
For our project, keeping it simple will probably be the best course of action, but it is interesting to see how this might be handled in a linked data environment--and to realize how important proper encoding of rights data could be in an environment where the images in your digital library could be linked to outside resources in unexpected or imagined ways.
Sunday, March 15, 2015
Gambling Underdog Westerns: How Netflix uses microtagging to give you what you want
Since it's Spring Break and Netflix is FAR more tempting than thinking about metadata, here's an excuse to think about Netflix and metadata at the same time. Imagine the football image library one could build with the infrastructure, algorithms, staff, and finances of Netflix!
Because recommendations are an important way to drive viewership and improve the user experience, Netflix uses 76,897 micro-genres to tag its videos. The combination of these tags results in those strange, wonderful, and oddly specific row headings like "Cerebral Romantic Thrillers from the 1980's." But to someone studying metadata and digital libraries, the story of how Netflix tags those videos and organizes that information is almost as interesting as the results, and Alexis Madrigal tells all about it in this fascinating article in the Atlantic. I guarantee that you will want to go and read this article, but I'll share a few nuggets from it here:
Because recommendations are an important way to drive viewership and improve the user experience, Netflix uses 76,897 micro-genres to tag its videos. The combination of these tags results in those strange, wonderful, and oddly specific row headings like "Cerebral Romantic Thrillers from the 1980's." But to someone studying metadata and digital libraries, the story of how Netflix tags those videos and organizes that information is almost as interesting as the results, and Alexis Madrigal tells all about it in this fascinating article in the Atlantic. I guarantee that you will want to go and read this article, but I'll share a few nuggets from it here:
- Netflix uses a controlled vocabulary. For example, it's always "Western," never "Cowboy Movie" or "Horse Opera."
- Netflix builds its headings using a defined hierarchy and order--a method anyone familiar with Library of Congress Subject Headings will appreciate. Certain descriptors, like "Oscar-Winning," always go toward the front, while other descriptors, like time periods, always go toward the end. The author sums it up with this general formula: "Region + Adjectives + Noun Genre + Based On... + Set In... + From the... + About... + For Age X to Y."
- Netflix tagging is done by humans, who watch every video and tag everything. Many of the tags are scales of 1-5.
- Netflix uses an algorithm to analyze the tags and build the "personal genres" it displays for its users. Some genres, like "Feel-good," are based on a formula incorporating several tags.
- Netflix combines viewing data and tags to try to recommend videos it thinks you will like. The company believes that this is a better method than either relying on exclusively on your ratings or trying to recommend videos to you based on what other people watched.
And then there's the Perry Mason Effect... but you can read about that on your own!
One more bonus in the article: it includes a "Netflix-Genre Generator" where you can generate your very own personal genres (it includes the alternative "Gonzo" setting (must be experienced) and the bland "Hollywood" setting (that explains most of the movies Hollywood churns out)). Give it a try!
Linked Data, BIBFRAME, and search
This week's reading included several interesting articles on linked data and libraries, including this Library Journal blog post by Enis, this post by Owens, this post by O'Dell, and this article by Gonzales. All of these articles contained similar themes regarding the need to move away from the inflexible MARC format and toward something more amenable to web searching. Some of the problems with current library catalogs include archaic search interfaces, record formats unfriendly to web-based and other "non-print" resources, and their invisibility to search engines.
The hope for BIBFRAME is that it would provide a way forward from MARC and allow library collections to be linked in intuitive and useful ways, so that authors, for example, might be linked not just to their works but perhaps also to members of their social group and events of the time and place where they lived. Perhaps a Google search would be able to easily connect potential users to the nearest available copies of a given book.
All of this is very exciting, and every indication is that this concept, or some aspect of it, will become a Real Thing in the next several years. However, I confess to a little skepticism as to how this will play out in actual practice. For a shared catalog system, among libraries in a system, consortium, regional area, perhaps the world, this could solve a lot of "shared collection" needs. Doing a Google search for something and getting a book from your local library in the top results would be pretty cool.
However, for general web searching, I worry about electronic resources and the issue of authentication and restricted, licensed access. Getting inaccessible results in a Google search quickly dilutes its usefulness, so how, then, does the search handle this? Are the library's results pushed down in relevance or relegated to a "library" silo or special search (like Google Books, perhaps)? Does frustration with licensed access increase the push for Open Access? Or will most of the licensed resources be sufficiently obscure that the main recipients of those results likely be academics with ways of attaining access? Google already includes some licensed content in its regular search results, with some ways of authenticating users by IP address (I believe it does this with Elsevier ScienceDirect content), but it doesn't yet do this on the scale proposed by BIBFRAME. It will be interesting follow this over the next several years!
The hope for BIBFRAME is that it would provide a way forward from MARC and allow library collections to be linked in intuitive and useful ways, so that authors, for example, might be linked not just to their works but perhaps also to members of their social group and events of the time and place where they lived. Perhaps a Google search would be able to easily connect potential users to the nearest available copies of a given book.
All of this is very exciting, and every indication is that this concept, or some aspect of it, will become a Real Thing in the next several years. However, I confess to a little skepticism as to how this will play out in actual practice. For a shared catalog system, among libraries in a system, consortium, regional area, perhaps the world, this could solve a lot of "shared collection" needs. Doing a Google search for something and getting a book from your local library in the top results would be pretty cool.
However, for general web searching, I worry about electronic resources and the issue of authentication and restricted, licensed access. Getting inaccessible results in a Google search quickly dilutes its usefulness, so how, then, does the search handle this? Are the library's results pushed down in relevance or relegated to a "library" silo or special search (like Google Books, perhaps)? Does frustration with licensed access increase the push for Open Access? Or will most of the licensed resources be sufficiently obscure that the main recipients of those results likely be academics with ways of attaining access? Google already includes some licensed content in its regular search results, with some ways of authenticating users by IP address (I believe it does this with Elsevier ScienceDirect content), but it doesn't yet do this on the scale proposed by BIBFRAME. It will be interesting follow this over the next several years!
Rights Element: Firm but friendly
Now that the Rights Element has safely retained its place on the island, I'm starting to think about what it should contain. Dr. MacCall made a very interesting point in class, that the Rights Element needs to be carefully balanced. There's an inherent conflict in placing images in a digital library, available to the world--if we didn't want people to enjoy and use the images, we wouldn't go to the time, effort, and expense of making them available; on the other hand, we have to protect the copyright of the images, the wishes of the rightsholder, and the possible revenue stream use of the images might generate. Therefore, the language in the Rights Element needs to be firm and clear, yet welcoming.
In thinking about this element, I can see that repeatability probably aids clarity. A simple copyright statement stands alone, and is clear and neutral. Information for actually contacting the Bryant Museum or the University of Alabama regarding permission is best handled through a link to the contact page for easier maintenance. But what about that welcoming part?
Tonya helpfully provided a link to the Minnesota Digital Library guidelines in this post, and they are clear and simple. However, I found their Rights example to be a little off-putting from the user perspective: "This image may not be reproduced for any reason without the express written consent...." It's clear, it's firm, but it's not very friendly. I wonder if it would be better to phrase it more like "Interested in using this image? Express written permission is required for all uses. Please contact ... "
What do you all think? Is it more important to invite usage or to discourage unauthorized usage? Can both be accomplished?
In thinking about this element, I can see that repeatability probably aids clarity. A simple copyright statement stands alone, and is clear and neutral. Information for actually contacting the Bryant Museum or the University of Alabama regarding permission is best handled through a link to the contact page for easier maintenance. But what about that welcoming part?
Tonya helpfully provided a link to the Minnesota Digital Library guidelines in this post, and they are clear and simple. However, I found their Rights example to be a little off-putting from the user perspective: "This image may not be reproduced for any reason without the express written consent...." It's clear, it's firm, but it's not very friendly. I wonder if it would be better to phrase it more like "Interested in using this image? Express written permission is required for all uses. Please contact ... "
What do you all think? Is it more important to invite usage or to discourage unauthorized usage? Can both be accomplished?
Thursday, March 5, 2015
Building controlled vocabularies
I'm a huge fan of using controlled vocabularies for even relatively small tasks. I've been known to hand out journal spreadsheets to subject specialists with renewal decision options locked into drop-down menus to discourage their use of creative, difficult-to-interpret language. And I still grumble about the co-workers who designated items bought with a small pool of special funds with the following notes in our ILS order records: "One-time funds," "One time $," "1-time funds," "1 time $," "1X funds," and "1X $." Seriously, try finding all of those variations with nothing but a text-string based search function!
Needless to say, I was quite interested in this article on how to build controlled vocabularies. The first thing I learned was that, while "controlled vocabulary" is often used generically, there is a specific hierarchy described by different terms. A controlled vocabulary on its own is just a specific list of terms where only terms from that list can be used for certain purposes. A simple example is a list of library locations--"REF," "Children's," "YA," etc. that are consistently used in the catalog. A taxonomy is a controlled vocabulary too, but it has a hierarchical structure of parent/child relationships between the terms, suggesting that it is likely larger and more complex. The list of library locations could be part of a larger taxonomy that is all the controlled vocabularies in the ILS--item locations, fund codes, patron classes, and so on. A thesaurus is even more complicated--like a taxonomy, only with more relationships. Think of LCSH with its various relationships--not just broader term and narrower term (parent/child) but also related term, and use/use for (older term/newer term).
The article's advice for developing a controlled vocabulary (CV) can be condensed down to the following suggestions:
Needless to say, I was quite interested in this article on how to build controlled vocabularies. The first thing I learned was that, while "controlled vocabulary" is often used generically, there is a specific hierarchy described by different terms. A controlled vocabulary on its own is just a specific list of terms where only terms from that list can be used for certain purposes. A simple example is a list of library locations--"REF," "Children's," "YA," etc. that are consistently used in the catalog. A taxonomy is a controlled vocabulary too, but it has a hierarchical structure of parent/child relationships between the terms, suggesting that it is likely larger and more complex. The list of library locations could be part of a larger taxonomy that is all the controlled vocabularies in the ILS--item locations, fund codes, patron classes, and so on. A thesaurus is even more complicated--like a taxonomy, only with more relationships. Think of LCSH with its various relationships--not just broader term and narrower term (parent/child) but also related term, and use/use for (older term/newer term).
The article's advice for developing a controlled vocabulary (CV) can be condensed down to the following suggestions:
- Define the scope of the CV--how large and complicated does it need to be, and what does it actually need to encompass?
- Find good sources for vocabulary--representative content, subject matter experts, search logs (what search terms do your users consistently use?), and existing taxonomies. Consider simply licensing an existing taxonomy if it satisfies your needs.
- Have a plan for keeping it updated. Things change--new technologies appear, and terminology changes over time.
- Gather terms using your subject matter experts and/or representative documents. Organize them into broad categories including parent/child, related term, and preferred/non-preferred terms. Use dedicated software to manage terms. Creating a graphic representation of the taxonomy may assist with review and categorization.
- Export the terms into a machine-readable language for better machine interpretation on the web.
- Review and validate the final product, and make sure to incorporate review and validation into the maintenance plan.
- Post the new CV to a registry or data warehouse where others can make use of it.
The Rights Element connected to the Source Element
(Edited now that I think I have a better grip on Source, "the most ambiguous, misunderstood, and misused of the 15 core elements.")
Last night I was discussing our assigned project elements with my course group, which includes Adam, Amy, and Katie. I find it interesting how our different elements interact. In particular, I think my element, Rights, could be related to Katie's element, Source.
Over in her blog, Katie wonders whether Source will be useful for this project, primarily because we don't yet know if all images will have an identifiable source, or if we'll be given more detailed information regarding the original images our images are derived from (our 2009 images were likely born digital, but the images from 1975 would have an original somewhere). Her question has a lot of bearing on my element, too, because the Rights for each image may be based on whatever rules govern use of the Source.
Our textbook defines the Rights element quite simply as "'Information about rights held in and over the resource' ... [including] intellectual property rights." Depending on circumstances, the Rights element might hold a very simple statement like "Copyright (c)2009 Paul W. Bryant Museum" but it could also include restrictions on use, such as "Written permission required" or "Noncommercial reuse only."
Importantly, the Rights may vary depending on whether someone wants to use the digital surrogate or needs to use a higher-resolution copy or get access to the original photograph or slide. Alternatively, the Rights may not vary from original to digital copy, but whatever Rights govern the original may also govern the copy. The Rights element, like many Dublin Core elements, may also contain information pertaining to the original image as well as to the digital version. In any of these cases, the data in the Source element would help to both clarify and validate the Rights information.
Last night I was discussing our assigned project elements with my course group, which includes Adam, Amy, and Katie. I find it interesting how our different elements interact. In particular, I think my element, Rights, could be related to Katie's element, Source.
Over in her blog, Katie wonders whether Source will be useful for this project, primarily because we don't yet know if all images will have an identifiable source, or if we'll be given more detailed information regarding the original images our images are derived from (our 2009 images were likely born digital, but the images from 1975 would have an original somewhere). Her question has a lot of bearing on my element, too, because the Rights for each image may be based on whatever rules govern use of the Source.
Our textbook defines the Rights element quite simply as "'Information about rights held in and over the resource' ... [including] intellectual property rights." Depending on circumstances, the Rights element might hold a very simple statement like "Copyright (c)2009 Paul W. Bryant Museum" but it could also include restrictions on use, such as "Written permission required" or "Noncommercial reuse only."
Importantly, the Rights may vary depending on whether someone wants to use the digital surrogate or needs to use a higher-resolution copy or get access to the original photograph or slide. Alternatively, the Rights may not vary from original to digital copy, but whatever Rights govern the original may also govern the copy. The Rights element, like many Dublin Core elements, may also contain information pertaining to the original image as well as to the digital version. In any of these cases, the data in the Source element would help to both clarify and validate the Rights information.
What do libraries want? It's the metadata, ALL the metadata.
This post was inspired by a suggestion from Damen:
For three days, I paid close attention, took good notes, and dutifully listened as the vendors demonstrated their systems according to our requested scenarios. They tried their best. They sent their biggest guns. Their systems all looked fantastic ... if it was 2005.
They all had workable models for dealing with print. They had terrific print circulation statistics, which they wasted far too much time in demonstrating. But the closer to present needs they got, and the more they had been called upon to serve our future needs, the less they had, and the less they even seemed to grasp what we wanted. So many things were still in development, or on some vague roadmap, or minimally coming "in 2016," and we're talking functionality we need RIGHT NOW TODAY. One even prefaced his recitation of potentially supported COUNTER usage reports with the word "NISObabble." I can't even conceive of a professional situation in which that kind of snark would be appropriate, but in my mind it absolutely summed up where their development priorities lay. In sum, those three days were more dispiriting than I could ever have imagined when we began this process well over a year ago. Maybe this process will end in a deal, and maybe it won't--I'm not in a position to vote--but whatever happens, I can see it will be a long road before we have the system we actually need.
So what do our campus libraries want? And why do we want it? Maybe we didn't make it clear. This is my view and only my view, informed by what our system discussed, but I do not speak for that system. I also won't speak to which vendors may or may not meet these needs, or in what way. One thing is obvious in looking at our needs: it does indeed have a lot to do with metadata.
"As I thought about metadata, reclined in my seat at the Intercontinental Chicago, watching the cars and people hurry about on Michigan Avenue, I realized that this had a lot to do with metadata, and ordered another steak from room service."As I thought about metadata, slumped in my seat at the Hilton, after yet another full day of library software demonstrations from vendors I'm not allowed to name, I realized that this had a lot to do with metadata, and wished I could order a new set of vendors from room service.
For three days, I paid close attention, took good notes, and dutifully listened as the vendors demonstrated their systems according to our requested scenarios. They tried their best. They sent their biggest guns. Their systems all looked fantastic ... if it was 2005.
They all had workable models for dealing with print. They had terrific print circulation statistics, which they wasted far too much time in demonstrating. But the closer to present needs they got, and the more they had been called upon to serve our future needs, the less they had, and the less they even seemed to grasp what we wanted. So many things were still in development, or on some vague roadmap, or minimally coming "in 2016," and we're talking functionality we need RIGHT NOW TODAY. One even prefaced his recitation of potentially supported COUNTER usage reports with the word "NISObabble." I can't even conceive of a professional situation in which that kind of snark would be appropriate, but in my mind it absolutely summed up where their development priorities lay. In sum, those three days were more dispiriting than I could ever have imagined when we began this process well over a year ago. Maybe this process will end in a deal, and maybe it won't--I'm not in a position to vote--but whatever happens, I can see it will be a long road before we have the system we actually need.
So what do our campus libraries want? And why do we want it? Maybe we didn't make it clear. This is my view and only my view, informed by what our system discussed, but I do not speak for that system. I also won't speak to which vendors may or may not meet these needs, or in what way. One thing is obvious in looking at our needs: it does indeed have a lot to do with metadata.
- Tools for working with the print collection must reflect the reality of shrinking holdings. They must support shared collection management, robust resource sharing, and easy flagging of last print copy. Special collections and digital libraries must be supported and foregrounded. This means shared, standardized metadata for bibliographic holdings, patron information, and loan rules; the system must support ways to ingest and/or discover metadata related to digital libraries, institutional repositories, and other locally-held content.
- Tools for acquiring new materials must support a high degree of automation and have the flexibility to handle individual and package purchases and subscriptions, as well as titles and packages procured through multiple consortia or demand-driven programs. This means support for EDI, KBART, and other major standards, and metadata exchange partnerships with vendors, aggregators and publishers, especially in scholarly fields.
- Tools for electronic resources must recognize the scale and complexity of academic collections. Many campuses are adopting "e-preferred" collection policies, and purchasing e-books on a scale unheard of in the days of print. The "million volume" e-book collection is already attainable. This means that systems must be able to handle the tasks of activation, linking, authentication, and collection maintenance with minimal intervention from library staff. Ideally, consortial purchases should be maintainable at the consortial level, while still allowing for local additions and control. Electronic collections should be easily compared to existing print collections. Vendors should work with publishers to ensure that metadata standards and codes of practice such as KBART, TRANSFER and PIE-J are followed by all parties, and holdings data exchange should happen at the vendor-publisher level. Holdings metadata for both e-journals and e-books must be exportable in a useful format for use in 3rd-party applications such as RapidILL; direct partnerships would be even better. Finally, easy linking and authentication through course reserves and course management systems such as Blackboard and Moodle are a must.
- Tools for analysis and assessment must privilege electronic usage. As collections trend ever more toward electronic, development priorities need to emphasize more than print circulation statistics. While e-book usage and print book circulation are not directly comparable, each reflects a valid and important aspect of library usage; however, as libraries purchase more of their new materials in electronic formats, print usage moves to the "long tail" where it reflects niche collections and older volumes, and often becomes a tool for weeding rather than guiding new purchases. Usage for electronic resources is the new circulation count, informing purchases through a variety of evaluations--overall usage, cost-per-use, use by discipline, use by publication date, and attempted use ("turnaways"). Academic libraries spend hundreds of thousands of dollars on e-resources, pushing evaluation beyond collection development practice into important discussions regarding budgets and justification to campus stakeholders. This means at minimum that library management systems must support all reports designated standard under COUNTER release 4, for e-journals, e-books, databases, and multimedia, for all forms of usage including attempted usage. They must allow for those reports to be combined with cost data and discipline for thoughtful analysis, and they must be flexible enough to take advantage of the additional information present in reports showing usage of older or open access content.
Bottom line, libraries need to manage, share, and assess their entire collections. In the current state, and in the foreseeable future, no system can call itself a complete solution if it doesn't support all three of these needs.
Thursday, February 26, 2015
Rights metadata
The publication "Rights Metadata Made Simple" offers solid, easy-to-follow, no-excuses advice on incorporating rights metadata into a digital library. Basing her recommendations on copyrightMD, "an XML schema for rights metadata developed by the California Digital Library (CDL)," author Maureen Whalen includes the following suggestions:
- Capture fields such as title, that would normally be included in basic descriptive metadata anyway, in an automated manner if possible.
- Capture author information, including nationality, birth and death dates, from an authority file if possible.
- If the institution holds both the original work and a digital surrogate, separate rights metadata should be created and the two works should be clearly differentiated.
- Use controlled vocabulary to describe copyright status and publication status to ensure that data entry is consistent and conforms if possible to legal definitions.
- Recording the following set of data: creator information, year of creation, copyright status, publication status, and date(s) rights research was conducted, allows both internal and external users of the works "to make thoughtful judgments about how the law may affect use of the work."
- Researching and recording the rights information for the contents of a digital collection allows libraries, archives and museums to be more "responsible stewards of the works in our collections and the digital surrogates of those works that we create."
- Rights information is not static--it may need to be added to or updated periodically; all staff involved in digitization efforts should know who is in charge of maintaining rights information and how to contact them when new information is learned.
As a final piece of advice, Whalen reminds libraries that, while determining consistent local policies for situations where little copyright or publication is known are important, this should not be used as an excuse for delaying--institutions can start by recording the rights information that is already known and deal with the rest over time.
The Wayback Machine and the Cornell Web Lab
The D-Lib article "A Research Library Based on the Historical Collections of the Internet Archive," published in February 2006, describes an initiative at Cornell University to create a web archive for social science research in partnership with the Internet Archive.
While the Wayback Machine, described in this excellent January 2015 New Yorker article, archives as much of the web as it can (450 billion pages as of this writing), it is not indexed or readily searchable other than by URL or date. For social scientists looking to do serious analysis of social trends, more manageable (though still enormous), indexed collections are needed. Cornell's project aimed to harvest collections of archived web pages--approximately 10 billion at the time of the article--and develop methods of automated indexing to make them useful to researchers. Access would be through scripts or APIs. Designers envisioned researchers conducting projects to trace the development of ideas across the internet, follow the spread of rumors and news, and investigate the influence of social networks.
As William Arms, one of the developers of the Cornell project notes in this article from 2008, researchers were spending as much as 90% of their time simply obtaining and cleaning up their data. "The Web Lab's strategy," he explains, "is to copy a large portion of the Internet Archive's Web collection to Cornell, mount it on a powerful computer system, organize it so that researchers have great flexibility in how they use it, and provide tools and services that minimize the effort required to use the data in research."
The project exists today as the Cornell Web Lab, and though direct links to its site were returning errors as of this writing, a detailed description of current activities can be found on this faculty page, and the tools and services suite is still available through Sourceforge.
Wednesday, February 25, 2015
Superschema or Common Schema?
After reading the articles that inspired them (here and here), it was fun to compare Adam's blog post on the useful simplicity behind Dublin Core to Tonya's post on the plausibility of creating a superschema to rule them all. Using very basic set theory to describe these approaches, it seems to me that Dublin Core takes the approach of the intersection of metadata sets, while the superschema idea consists of the union of all metadata sets. Both ideas seem to posit a system in which all elements would be optional, using only those appropriate to the object being described. However, Dublin Core works by providing a limited number of common elements that can describe nearly anything generically, while the superschema would work by providing an almost unlimited number of elements that could describe nearly anything specifically. What an interesting contrast!
From a practical standpoint, DC has a lot to offer in terms of interoperability, maintainability, and the ease of building fast indexes with understandable browsing facets. The superschema idea would allow a lot of freedom, but describers would need to have a very broad knowledgebase, and even local systems based on it would be highly complex.
From the user's standpoint, what would the superschema system look like? I suspect that it would look a lot like Google. The search algorithm would probably need to rely on keywords, with relevancy heavily informed by the tags from the various schema (so your search for "sage in herbal remedies" wouldn't be swamped by articles published by SAGE Publishing). While I don't know how their proprietary indexing systems work, this sounds to me an awful lot like library discovery layers, and the direction they are moving in.
To me, the good news here is that the mix-and-match can, and probably will, happen at a higher level than the metadata schema. Individual systems could continue to use the specialty schema that work best. Knowing other schema is still important in case of migration, but hopefully combining datasets will come to rely on something more sophisticated than the most basic of crosswalks. It will be interesting to see where it all goes!
From a practical standpoint, DC has a lot to offer in terms of interoperability, maintainability, and the ease of building fast indexes with understandable browsing facets. The superschema idea would allow a lot of freedom, but describers would need to have a very broad knowledgebase, and even local systems based on it would be highly complex.
From the user's standpoint, what would the superschema system look like? I suspect that it would look a lot like Google. The search algorithm would probably need to rely on keywords, with relevancy heavily informed by the tags from the various schema (so your search for "sage in herbal remedies" wouldn't be swamped by articles published by SAGE Publishing). While I don't know how their proprietary indexing systems work, this sounds to me an awful lot like library discovery layers, and the direction they are moving in.
To me, the good news here is that the mix-and-match can, and probably will, happen at a higher level than the metadata schema. Individual systems could continue to use the specialty schema that work best. Knowing other schema is still important in case of migration, but hopefully combining datasets will come to rely on something more sophisticated than the most basic of crosswalks. It will be interesting to see where it all goes!
Thursday, February 19, 2015
Perma.cc: Addressing link rot in legal scholarship
I've written several posts on the subject of persistent identifiers, especially DOI, and their importance in maintaining access and enabling permanent cross-referencing and citation. However, DOI is intended for stable objects, primarily version-of-record scholarly publications (articles, chapters, etc.). Blog posts, websites, wikis, social media, and similar Internet content can also be useful for research, but authors are forced to fall back on including ordinary URLs when citing these sources. This problem has been specifically documented in legal scholarship--when Harvard Law School researchers recently surveyed the state of legal citations, they made the disturbing finding that "more than 70% of the URLs within the Harvard Law Review and other journals, and 50% of the URLs found within United States Supreme Court opinions, do not link to the originally cited information."
In response, an online preservation service called Perma.cc was "developed by the Harvard Law School Library in conjunction with university law libraries." Perma.cc works like this: if an author wants to cite a website or other online source that lacks a permanent identifier, he or she can go to the Perma.cc site and input the URL. Perma.cc downloads and archives the content at that URL and returns a perma.cc link to the researcher, who then uses it in the citation. When the article is submitted for publication to a participating journal, the journal staff check the perma.cc link for accuracy and then "vest" it for permanent archiving. Readers who click the link are taken to a page that offers a choice of the current live page, the archived page (which may not include linked content such as graphics), and an archived screen shot (which will not include live links). Sites that do not want Perma.cc to make their content publicly available can opt out through a metatag or robots.txt file; in these cases, Perma.cc will place the page content in a dark archive, accessible only to the citing author and vesting organization. Interestingly, Perma.cc still harvests the content, even though it doesn't make it publicly available.
It will be interesting to see if this service (which is still in beta as of this writing) is successful, and if it expands beyond the legal field. It seems to me to be an excellent companion to DOI, as DOI gets around the problem of copyrighted, toll access content by maintaining only links, rather than archiving content, while Perma.cc provides the same level of stability for freely-accessible but less stable web content.
In response, an online preservation service called Perma.cc was "developed by the Harvard Law School Library in conjunction with university law libraries." Perma.cc works like this: if an author wants to cite a website or other online source that lacks a permanent identifier, he or she can go to the Perma.cc site and input the URL. Perma.cc downloads and archives the content at that URL and returns a perma.cc link to the researcher, who then uses it in the citation. When the article is submitted for publication to a participating journal, the journal staff check the perma.cc link for accuracy and then "vest" it for permanent archiving. Readers who click the link are taken to a page that offers a choice of the current live page, the archived page (which may not include linked content such as graphics), and an archived screen shot (which will not include live links). Sites that do not want Perma.cc to make their content publicly available can opt out through a metatag or robots.txt file; in these cases, Perma.cc will place the page content in a dark archive, accessible only to the citing author and vesting organization. Interestingly, Perma.cc still harvests the content, even though it doesn't make it publicly available.
It will be interesting to see if this service (which is still in beta as of this writing) is successful, and if it expands beyond the legal field. It seems to me to be an excellent companion to DOI, as DOI gets around the problem of copyrighted, toll access content by maintaining only links, rather than archiving content, while Perma.cc provides the same level of stability for freely-accessible but less stable web content.
Wednesday, February 18, 2015
Special Collections and Scholarly Communications
Donald Waters' thoughts on The Changing Role of Special Collections in Scholarly Communications come from the broad perspective of a funding organization (The Andrew W. Mellon Foundation), which allows him an informed view of the world of special collections without the potential bias of someone deeply invested in a specific project. Though written five years ago, this piece is still relevant.
Regarding Waters' opinion on the relative commonness or distinctiveness of collections, I think it is important to distinguish between current material and archival material. As scholarly publishing is ever more thoroughly packaged and sold in huge lots (subject or title collections sold by publishers or "complete" aggregations from EBSCO, ProQuest, and others), and purchases consolidate at the level of the library consortium, homogenization of basic research holdings is an inevitable outcome. On the other hand, as libraries are increasingly pressed to make space for more social or student-centered needs within their existing footprints, legacy print collections are indeed likely to become more distinctive, a boutique selection tailored to specific campus needs. This will probably be most noticeable at smaller, non-PHD-granting institutions where it is difficult to make a value case for what one of my bosses called "the book museum" model. These smaller collections will rely more heavily on sharing arrangements with other institutions, with expanded metadata requirements to ensure discoverability and support collection management at individual campuses (e.g. which library holds, or will hold, the last print copy of a title, allowing others to discard the local copy).
I think Waters makes a terrific suggestion that special collections librarians work with the scholars at their institution to prioritize which collections are digitized and processed. Given the huge backlogs and extraordinarily varied nature of most collections, accommodating current faculty needs seems like an excellent way to direct the workflow, justify the expenditure to campus stakeholders, and build important bridges between the library and faculty researchers.
Another great idea in theory is having researchers assign metadata to the materials they are working on. I think this would work well in the examples cited, where the researcher is working on a fellowship. It's a great way to "pay forward" some of the grant money, and leverages the deep subject knowledge of the researcher. However, I think the system would not scale well to the larger world of all digital libraries and special collections. Faculty balancing research, teaching, and administrative duties are unlikely to be interested in "helping" the library, or have the spare time to commit even if they were; thus the metadata tasks would either go undone or be relegated to graduate students who might or might not have the expertise or commitment necessary to do the job well.
I had the pleasure last semester of interviewing Dr. Sylvia Huot, a scholar involved in the early development of one of the Mellon-funded projects mentioned in the article, The Roman de la Rose Digital Library. In regard to their original plans for full transcription and tagging, she told me that despite small volunteer transcription projects going on at various universities involved in the project, the leaders eventually realized how impractical it was to attempt transcription of the entire library and were forced to abandon the effort. "No one with the skills to do a proper transcription job was willing or able to volunteer, and it would have required an enormous influx of funding to hire even skilled graduate students to complete the work."
There is little doubt of the value of excellent metadata, accurate transcriptions, open availability, and cross-institution linking and discovery for special collections. Usage begets citations begets more usage, which pleases stakeholders and funding organizations and leads to more digitization projects in a virtuous cycle. However, there must be a better way than simply shifting the burden from one constituency to another. There must be either greater efficiency, perhaps through automation or better tools, or greater funding, if this valuable goal is to be reached.
Regarding Waters' opinion on the relative commonness or distinctiveness of collections, I think it is important to distinguish between current material and archival material. As scholarly publishing is ever more thoroughly packaged and sold in huge lots (subject or title collections sold by publishers or "complete" aggregations from EBSCO, ProQuest, and others), and purchases consolidate at the level of the library consortium, homogenization of basic research holdings is an inevitable outcome. On the other hand, as libraries are increasingly pressed to make space for more social or student-centered needs within their existing footprints, legacy print collections are indeed likely to become more distinctive, a boutique selection tailored to specific campus needs. This will probably be most noticeable at smaller, non-PHD-granting institutions where it is difficult to make a value case for what one of my bosses called "the book museum" model. These smaller collections will rely more heavily on sharing arrangements with other institutions, with expanded metadata requirements to ensure discoverability and support collection management at individual campuses (e.g. which library holds, or will hold, the last print copy of a title, allowing others to discard the local copy).
I think Waters makes a terrific suggestion that special collections librarians work with the scholars at their institution to prioritize which collections are digitized and processed. Given the huge backlogs and extraordinarily varied nature of most collections, accommodating current faculty needs seems like an excellent way to direct the workflow, justify the expenditure to campus stakeholders, and build important bridges between the library and faculty researchers.
Another great idea in theory is having researchers assign metadata to the materials they are working on. I think this would work well in the examples cited, where the researcher is working on a fellowship. It's a great way to "pay forward" some of the grant money, and leverages the deep subject knowledge of the researcher. However, I think the system would not scale well to the larger world of all digital libraries and special collections. Faculty balancing research, teaching, and administrative duties are unlikely to be interested in "helping" the library, or have the spare time to commit even if they were; thus the metadata tasks would either go undone or be relegated to graduate students who might or might not have the expertise or commitment necessary to do the job well.
I had the pleasure last semester of interviewing Dr. Sylvia Huot, a scholar involved in the early development of one of the Mellon-funded projects mentioned in the article, The Roman de la Rose Digital Library. In regard to their original plans for full transcription and tagging, she told me that despite small volunteer transcription projects going on at various universities involved in the project, the leaders eventually realized how impractical it was to attempt transcription of the entire library and were forced to abandon the effort. "No one with the skills to do a proper transcription job was willing or able to volunteer, and it would have required an enormous influx of funding to hire even skilled graduate students to complete the work."
There is little doubt of the value of excellent metadata, accurate transcriptions, open availability, and cross-institution linking and discovery for special collections. Usage begets citations begets more usage, which pleases stakeholders and funding organizations and leads to more digitization projects in a virtuous cycle. However, there must be a better way than simply shifting the burden from one constituency to another. There must be either greater efficiency, perhaps through automation or better tools, or greater funding, if this valuable goal is to be reached.
Expanding linked data: Why isn't this done?
JPow asks an excellent question in his LS blog: Why can't citation data (cited and cited by) be included in surrogate records?
I'm going to talk about this in terms of discovery layers rather than online catalogs, because online catalogs are typically very basic, MARC-based software that is fading rapidly into the background of library systems.
I think that JPow's concept could be implemented using a combination of CrossRef, Web of Science, and Scopus -- a terrific idea, and one that is implemented already to some degree, in some discovery systems, but definitely not to any universal extent.
What's the catch? I suspect that it's mostly about money and proprietary data. Citation indexes like Web of Science and Scopus are very expensive to maintain, and very big money makers for the companies that own them. They are willing to share basic indexing and citation metadata with the discovery services, but part of the agreement is that libraries must ALSO have licensed the databases separately before they are allowed to see results from those databases included in the discovery layer, and even then much of the "secret sauce" of citation tracing and other advanced functionality isn't included. (In fairness, quite a bit of this wouldn't easily translate to the simpler discovery interface.)
What I haven't seen implemented yet is CrossRef, and that has interesting potential. I think that one catch there is that it tends to be implemented as part of the full text of articles, in the references section. That section of the full text would perhaps have to be separated in some way and included in the metadata stored by the discovery service. I think that's possible, though I don't know if any systems are doing it currently. I think authentication could be the other tricky piece, since CrossRef links directly through DOI. This isn't a huge issue for on-campus users (who are generally authenticated by IP address) but directing off-campus users through the right hoops (proxy server, Shibboleth, etc.) is a potential hurdle.
I did check my library's discovery system (ProQuest Summon) and found that it offers our users "People who read this journal article also read" article links attached to records it gets from Thomson Reuters Web of Science. On the other hand, it doesn't offer any extra links for records it gets from Elsevier (ScienceDirect and Scopus). We see the Web of Science information because we've separately licensed those indexes from Thomson Reuters, and that means Summon is "allowed" to show us those records. We don't see the citation links from Scopus because we haven't licensed that product, so Summon isn't allowed to present any results from that dataset. I also find it interesting that Web of Science appears to share usage-based metadata but is not sharing citation-based metadata; I'm guessing maybe they see that as potentially too cannibalistic to their own service.
So, the short answer? JPow is asking for a rabbit, yes, and it's not from a hat, but from a deep and twisty rabbit hole. I don't think it's asking too much, though I do think it would be expensive.
I'm going to talk about this in terms of discovery layers rather than online catalogs, because online catalogs are typically very basic, MARC-based software that is fading rapidly into the background of library systems.
I think that JPow's concept could be implemented using a combination of CrossRef, Web of Science, and Scopus -- a terrific idea, and one that is implemented already to some degree, in some discovery systems, but definitely not to any universal extent.
What's the catch? I suspect that it's mostly about money and proprietary data. Citation indexes like Web of Science and Scopus are very expensive to maintain, and very big money makers for the companies that own them. They are willing to share basic indexing and citation metadata with the discovery services, but part of the agreement is that libraries must ALSO have licensed the databases separately before they are allowed to see results from those databases included in the discovery layer, and even then much of the "secret sauce" of citation tracing and other advanced functionality isn't included. (In fairness, quite a bit of this wouldn't easily translate to the simpler discovery interface.)
What I haven't seen implemented yet is CrossRef, and that has interesting potential. I think that one catch there is that it tends to be implemented as part of the full text of articles, in the references section. That section of the full text would perhaps have to be separated in some way and included in the metadata stored by the discovery service. I think that's possible, though I don't know if any systems are doing it currently. I think authentication could be the other tricky piece, since CrossRef links directly through DOI. This isn't a huge issue for on-campus users (who are generally authenticated by IP address) but directing off-campus users through the right hoops (proxy server, Shibboleth, etc.) is a potential hurdle.
I did check my library's discovery system (ProQuest Summon) and found that it offers our users "People who read this journal article also read" article links attached to records it gets from Thomson Reuters Web of Science. On the other hand, it doesn't offer any extra links for records it gets from Elsevier (ScienceDirect and Scopus). We see the Web of Science information because we've separately licensed those indexes from Thomson Reuters, and that means Summon is "allowed" to show us those records. We don't see the citation links from Scopus because we haven't licensed that product, so Summon isn't allowed to present any results from that dataset. I also find it interesting that Web of Science appears to share usage-based metadata but is not sharing citation-based metadata; I'm guessing maybe they see that as potentially too cannibalistic to their own service.
So, the short answer? JPow is asking for a rabbit, yes, and it's not from a hat, but from a deep and twisty rabbit hole. I don't think it's asking too much, though I do think it would be expensive.
Friday, February 13, 2015
Fire up the Serendipity Engine, Watson!
So, now that I've bashed the whole idea of serendipity in an earlier post and stressed the importance of both "good enough" discovery and teaching users to effectively utilize the tools we give them, I'm going to go off in a totally different direction and write about something completely whimsical. The terrific article by Patrick Carr that I referenced in my earlier post mentioned a site called Serendip-o-matic. Serendip-o-matic bills itself as a Serendipity Engine that aims to help the user "discover photographs, documents, maps and other primary sources" by "first examining your research interests, and then identifying related content in locations such as the Digital Public Library of America (DPLA), Europeana, and Flickr Commons."
How does the Serendipity Engine work? You paste text into its search box--from your own paper, an article source, a Wikipedia entry, or anything else that seems like a useful place to start--and click the Make some magic! button. The application extracts keywords from that text snippet and looks for matches in the metadata available from its sources, returning a list of loosely related content (mostly images at this point in its development).
The idea behind Serendip-o-matic is the very opposite of most search engines or discovery systems, which seek to deliver results that are as relevant as possible. In fact, the whole point of the Serendipity Engine is to deliver the unexpected, yet somehow related, item that will loosen the writer's block, send the mind whirling in a fresh direction, or make the connection the brain sensed but couldn't quite reach.
Metadata makes magic! Try it and see what you think.
How does the Serendipity Engine work? You paste text into its search box--from your own paper, an article source, a Wikipedia entry, or anything else that seems like a useful place to start--and click the Make some magic! button. The application extracts keywords from that text snippet and looks for matches in the metadata available from its sources, returning a list of loosely related content (mostly images at this point in its development).
The idea behind Serendip-o-matic is the very opposite of most search engines or discovery systems, which seek to deliver results that are as relevant as possible. In fact, the whole point of the Serendipity Engine is to deliver the unexpected, yet somehow related, item that will loosen the writer's block, send the mind whirling in a fresh direction, or make the connection the brain sensed but couldn't quite reach.
Metadata makes magic! Try it and see what you think.
Thursday, February 12, 2015
TEI and Comic Books
The Text Coding Initiative (TEI) defines a set of guidelines for encoding digital texts. TEI encoding does much more than just make texts readable on the Internet--it allows for important bibliographic metadata to be associated with the text, and also makes it possible to encode structural features of the text (such as rhyme schemes, utterances, and character names) to enable better retrieval and deeper analysis. TEI by Example is a good place to get a quick taste of what TEI consists of--Section 5 TEI: Ground Rules stands by itself and is relatively easy to understand.
While TEI Lite, a subset of TEI "designed to meet '90% of the needs of 90% of the TEI user community'" is widely used, TEI is also extensible, allowing for customization to meet the needs of a specific project. One fun example of this is Comic Book Markup Language, developed by John Walsh. This extension allows for encoding of comics and graphic novels, including structural features such as panels and speech bubbles, and sound effects such as "ZAP!" This slide deck from a Charleston Conference 2014 presentation on CBML (screen will appear blank--click the arrows or use left/right arrow keys) explains further about CBML and also provides a useful example of TEI in action.
While TEI Lite, a subset of TEI "designed to meet '90% of the needs of 90% of the TEI user community'" is widely used, TEI is also extensible, allowing for customization to meet the needs of a specific project. One fun example of this is Comic Book Markup Language, developed by John Walsh. This extension allows for encoding of comics and graphic novels, including structural features such as panels and speech bubbles, and sound effects such as "ZAP!" This slide deck from a Charleston Conference 2014 presentation on CBML (screen will appear blank--click the arrows or use left/right arrow keys) explains further about CBML and also provides a useful example of TEI in action.
Wednesday, February 11, 2015
Discovery vs Serendipity
I found the responses to "How far should we go with ‘full library discovery’?" from several of my fellow students to be quite interesting. I noticed that MetaWhat!Data! allowed for the idea that others might find full library discovery to be overload, but she herself liked the idea of "going further down the rabbit hole of discovery." I'm always interested in what people would like more of in their library systems, so I wish she would have actually elaborated a bit more on that. JPow, on the other hand, decided to test different systems and report on the differences, always a useful exercise. I enjoyed his fresh perspective and choice to concentrate on pre-filtering capabilities. I wonder what sort of user studies these systems may (or may not) have regarding whether or not the typical user prefers to refine up-front or after receiving results. MadamLibrarian makes an excellent point about the importance of transparency in discovery and making it clear what isn't being searched. How does a library assess the opportunity cost of a discovery system. MetaDamen brought up very good objections to the use of peer data and previous searches, and Adam raised an important issue regarding next-gen search capabilities and the need for both strict disclosure and an opt-out feature.
Finally, there was much discussion about serendipity and the importance of maintaining an active role in the research process. This is the point where I will choose to be a bit of a contrarian and push back a little. First, let's look at passivity versus mindfulness in the research process. I've worked reference shifts for years, both virtual reference and in-person, and my totally biased opinion is that the mindfulness of the research/writing/learning process really doesn't occur during the "source harvesting" stage, at least not for your average college student. It doesn't matter whether we're talking about the old bound volumes of the Reader's Guide, its newer incarnation in Academic Search Complete, or the latest discovery system, that process involves hoovering up as many articles and books that seem to fit the topic, and winnowing them down later. There's plenty of mindfulness in choosing and narrowing that topic, and plenty later in the reading, synthesis, and writing, but the harvesting? Not so much. If the search isn't going well enough to "satisfice," there's always the helpful librarian ready to offer controlled vocabulary and search tips, at the teachable moment. A better discovery system is like a better car in this case--you may spend less time looking at the scenery as you whiz past, but it was only the strip mall beside the interstate anyway, and you have more time to enjoy your destination.
But what about the serendipity? Serendipity is such a romantic ideal. But why is it that people wax all poetic over a random misshelving in the book stacks, but deny it in the case of a metadata error? Why can't an automated system provide serendipity in searching--indeed, why can't an automated system do a better job of offering it up? In the classic print-only library, if you have a book about both cats and airplanes, you can only shelve it with the cat books or the airplane books, probably on completely separate floors, if not in separate branches. Which set of users gets the serendipity, and which set misses out entirely? On the other hand, if there's a book on cats and airplanes in the library, your discovery system can present it in the results whether you searched for cats or airplanes. Some librarians go even further and suggest that serendipity in the stacks is a negative concept. The Ubiquitous Librarian "would rather teach students to be good searchers instead of lucky ones." Donald Barclay compares browsing the stacks to "hitting the 3-day sales tables" and notes that discovery systems open a world of shared collections much better and more efficient than what any one library can house. Patrick Carr argues in "Serendipity in the Stacks: Libraries, Information Architecture, and the Problems of Accidental Discovery" that "from a perception-based standpoint, serendipity is problematic because it can encourage user-constructed meanings for libraries that are rooted in opposition to change rather than in users’ immediate and evolving information needs." He suggests that libraries strive to develop "information architectures that align outcomes with user intentions and that invite users to see beyond traditional notions of libraries." Perhaps what is really needed is for libraries to repurpose the notion of serendipity and show users how to generate magical results with better searching techniques in better systems.
Finally, there was much discussion about serendipity and the importance of maintaining an active role in the research process. This is the point where I will choose to be a bit of a contrarian and push back a little. First, let's look at passivity versus mindfulness in the research process. I've worked reference shifts for years, both virtual reference and in-person, and my totally biased opinion is that the mindfulness of the research/writing/learning process really doesn't occur during the "source harvesting" stage, at least not for your average college student. It doesn't matter whether we're talking about the old bound volumes of the Reader's Guide, its newer incarnation in Academic Search Complete, or the latest discovery system, that process involves hoovering up as many articles and books that seem to fit the topic, and winnowing them down later. There's plenty of mindfulness in choosing and narrowing that topic, and plenty later in the reading, synthesis, and writing, but the harvesting? Not so much. If the search isn't going well enough to "satisfice," there's always the helpful librarian ready to offer controlled vocabulary and search tips, at the teachable moment. A better discovery system is like a better car in this case--you may spend less time looking at the scenery as you whiz past, but it was only the strip mall beside the interstate anyway, and you have more time to enjoy your destination.
But what about the serendipity? Serendipity is such a romantic ideal. But why is it that people wax all poetic over a random misshelving in the book stacks, but deny it in the case of a metadata error? Why can't an automated system provide serendipity in searching--indeed, why can't an automated system do a better job of offering it up? In the classic print-only library, if you have a book about both cats and airplanes, you can only shelve it with the cat books or the airplane books, probably on completely separate floors, if not in separate branches. Which set of users gets the serendipity, and which set misses out entirely? On the other hand, if there's a book on cats and airplanes in the library, your discovery system can present it in the results whether you searched for cats or airplanes. Some librarians go even further and suggest that serendipity in the stacks is a negative concept. The Ubiquitous Librarian "would rather teach students to be good searchers instead of lucky ones." Donald Barclay compares browsing the stacks to "hitting the 3-day sales tables" and notes that discovery systems open a world of shared collections much better and more efficient than what any one library can house. Patrick Carr argues in "Serendipity in the Stacks: Libraries, Information Architecture, and the Problems of Accidental Discovery" that "from a perception-based standpoint, serendipity is problematic because it can encourage user-constructed meanings for libraries that are rooted in opposition to change rather than in users’ immediate and evolving information needs." He suggests that libraries strive to develop "information architectures that align outcomes with user intentions and that invite users to see beyond traditional notions of libraries." Perhaps what is really needed is for libraries to repurpose the notion of serendipity and show users how to generate magical results with better searching techniques in better systems.
Thursday, February 5, 2015
Identifier persistence
I agree with Madam Librarian that the article A Policy Checklist for Enabling Persistence of Identifiers was convoluted and difficult to follow in places. For the sake of my own understanding, I'll try to summarize here the basic points I got out of it. Maybe this will help others in the class as well.
The article presents a set of numbered questions, but then proceeds to address them in a completely different order while attempting to map them to a checklist, which is numbered in yet another style. For the sake of sanity, I will just briefly summarize the article's main points in the order presented, and present examples where it seems useful.
What should I identify persistently? Analyze your resources, decide which ones can be consistently identified in some way, and then prioritize these identifiable resources. There will probably be many items that have identifiers, but only a subset of these will require persistence; typically these would represent key access points for your user community.
What steps should I take to guarantee persistence? This is best handled through policies, supported by automation of processes. Information management should be decoupled from identifier management. In practice, this means that information within a system is identified and managed using local keys--e.g. this could be the URL for a journal article. However, the identifiers for this same information that are shared with outside entities--indexing services and library databases, e.g.--should be based on indirect identifiers, which can be updated when necessary in a way that is invisible to users.
An example of this is an article DOI. The hypothetical article "36 Tips for Awesomeness" (local identifier) is published in the Spring 2006 issue of Fabulous Journal, given a URL of www.fabulousjournal.com/36_Tips_for_Awesomeness (local identifier), and assigned a DOI of 10.8992/fj.1234 (persistent identifier). Over the next few years, the journal is bought by another publisher and all content is moved to www.awesomepublisher.com/journal/(ISSN)1000-0001. A year or two after that, the new publisher merges Fabulous Journal with Really Cool Journal, requests a new ISSN, and moves all content to www.awesomepublisher.com/journal/(ISSN)2002-200X. Awesome Publisher has good policies for persistence and updates DOI with each change. This is the result:
10.8992/fj.1234 initially points to www.fabulousjournal.com/36_Tips_for_Awesomeness
10.8992/fj.1234 then points to www.awesomepublisher.com/journal/(ISSN)1000-0001/36_Tips_for_Awesomeness
10.8992/fj.1234 currently points to www.awesomepublisher.com/journal/(ISSN)2002-200X/36_Tips_for_Awesomeness
As long as the services that refer to this article use the DOI instead of the article URL, it will remain accessible despite the changes going on in the background.
What technologies should I use to guarantee persistence? Whichever ones work best with your existing technology and workflow. It's more important that the process works seamlessly and with minimum effort than it is to commit to one specific technology, no matter what That One IT Guy in your division says.
How long should identifiers persist? The answer to this is, as long as is appropriate, but make sure that you (1) don't promise what you can't deliver (no one can actually guarantee "forever") and (2) are up-front about it ("provisions are in place to guarantee persistence for a minimum of 30 years beyond the online publication date" or "this link will expire in 7 days").
What do you mean by "persistent"? The article explains that there are degrees of persistence, and breaks them down into a list (I'll use the same article example to explain).
Persistence of Name or Association:
(1) The title "36 Tips for Awesomeness" will always be associated with that specific article on awesome tips--it won't suddenly be associated with an article on cattle diseases.
(2) The article may continue to be referred to in various places as www.fabulousjournal.com/36_Tips_for_Awesomeness even though that URL no longer works. In other words, the association persists in unmaintained places outside the control of the resource owner.
(3) The article will always be associated with DOI 10.8992/fj.1234, whether or not the publisher updates the DOI information when the article changes location.
Persistence of Service:
(1) Retrieval: Can the item still be obtained over the guaranteed time period? In the case of our article, two of the three listed URLs would eventually fail to retrieve the article, but the DOI should continue to work, resulting in retrieval of the article no matter where it is hosted.
(2) Resolution: A URL may resolve without resulting in a successful retrieval. For example, the original author of our 36 tips might get into a copyright dispute with the new publisher, resulting in the article being taken down. In this case, the publisher might arrange for the URL to resolve to a page with the basic metadata for the article and a brief note about the missing content. If the URL instead results in a "page not found" error, then it lacks persistent resolution.
Whether a service guarantees retrieval or resolution is an important distinction and should be clearly stated. Both retrieval and resolution are essential but different.
Persistence of Accountability:
This is mostly for archival purposes. Is some kind of metadata maintained that gives the history of who has created and edited a specific record?
TL;DR: Persistent identifier policies in an information management environment should clearly outline the following: which identifiers will be persistent, how persistence will be maintained, how long the user can expect persistence to last, and whether persistence guarantees access to a specific item (retrieval) or guarantees access to (at minimum) information about that item (resolution).
The article presents a set of numbered questions, but then proceeds to address them in a completely different order while attempting to map them to a checklist, which is numbered in yet another style. For the sake of sanity, I will just briefly summarize the article's main points in the order presented, and present examples where it seems useful.
What should I identify persistently? Analyze your resources, decide which ones can be consistently identified in some way, and then prioritize these identifiable resources. There will probably be many items that have identifiers, but only a subset of these will require persistence; typically these would represent key access points for your user community.
What steps should I take to guarantee persistence? This is best handled through policies, supported by automation of processes. Information management should be decoupled from identifier management. In practice, this means that information within a system is identified and managed using local keys--e.g. this could be the URL for a journal article. However, the identifiers for this same information that are shared with outside entities--indexing services and library databases, e.g.--should be based on indirect identifiers, which can be updated when necessary in a way that is invisible to users.
An example of this is an article DOI. The hypothetical article "36 Tips for Awesomeness" (local identifier) is published in the Spring 2006 issue of Fabulous Journal, given a URL of www.fabulousjournal.com/36_Tips_for_Awesomeness (local identifier), and assigned a DOI of 10.8992/fj.1234 (persistent identifier). Over the next few years, the journal is bought by another publisher and all content is moved to www.awesomepublisher.com/journal/(ISSN)1000-0001. A year or two after that, the new publisher merges Fabulous Journal with Really Cool Journal, requests a new ISSN, and moves all content to www.awesomepublisher.com/journal/(ISSN)2002-200X. Awesome Publisher has good policies for persistence and updates DOI with each change. This is the result:
10.8992/fj.1234 initially points to www.fabulousjournal.com/36_Tips_for_Awesomeness
10.8992/fj.1234 then points to www.awesomepublisher.com/journal/(ISSN)1000-0001/36_Tips_for_Awesomeness
10.8992/fj.1234 currently points to www.awesomepublisher.com/journal/(ISSN)2002-200X/36_Tips_for_Awesomeness
As long as the services that refer to this article use the DOI instead of the article URL, it will remain accessible despite the changes going on in the background.
What technologies should I use to guarantee persistence? Whichever ones work best with your existing technology and workflow. It's more important that the process works seamlessly and with minimum effort than it is to commit to one specific technology, no matter what That One IT Guy in your division says.
How long should identifiers persist? The answer to this is, as long as is appropriate, but make sure that you (1) don't promise what you can't deliver (no one can actually guarantee "forever") and (2) are up-front about it ("provisions are in place to guarantee persistence for a minimum of 30 years beyond the online publication date" or "this link will expire in 7 days").
What do you mean by "persistent"? The article explains that there are degrees of persistence, and breaks them down into a list (I'll use the same article example to explain).
Persistence of Name or Association:
(1) The title "36 Tips for Awesomeness" will always be associated with that specific article on awesome tips--it won't suddenly be associated with an article on cattle diseases.
(2) The article may continue to be referred to in various places as www.fabulousjournal.com/36_Tips_for_Awesomeness even though that URL no longer works. In other words, the association persists in unmaintained places outside the control of the resource owner.
(3) The article will always be associated with DOI 10.8992/fj.1234, whether or not the publisher updates the DOI information when the article changes location.
Persistence of Service:
(1) Retrieval: Can the item still be obtained over the guaranteed time period? In the case of our article, two of the three listed URLs would eventually fail to retrieve the article, but the DOI should continue to work, resulting in retrieval of the article no matter where it is hosted.
(2) Resolution: A URL may resolve without resulting in a successful retrieval. For example, the original author of our 36 tips might get into a copyright dispute with the new publisher, resulting in the article being taken down. In this case, the publisher might arrange for the URL to resolve to a page with the basic metadata for the article and a brief note about the missing content. If the URL instead results in a "page not found" error, then it lacks persistent resolution.
Whether a service guarantees retrieval or resolution is an important distinction and should be clearly stated. Both retrieval and resolution are essential but different.
Persistence of Accountability:
This is mostly for archival purposes. Is some kind of metadata maintained that gives the history of who has created and edited a specific record?
TL;DR: Persistent identifier policies in an information management environment should clearly outline the following: which identifiers will be persistent, how persistence will be maintained, how long the user can expect persistence to last, and whether persistence guarantees access to a specific item (retrieval) or guarantees access to (at minimum) information about that item (resolution).
Subscribe to:
Posts (Atom)